
Last year I wrote “Looking back at 2022” and found it valuable to reflect and celebrate a year of work, even if just as a reminder of the things that happened before going into the next.
So with another year having passed, time to try again! This time for my second full year working at incident.io.
To contextualise the year, some milestones (see company post) are:
- 34 to 77 employees
- Opened our first New York office, Stephen moving out to lead it
- Shipped two new products: Status Pages and Catalog
I always start these posts by listing everything that comes to mind over the last year, finding common themes, then deciding on a structure to best communicate them.
This year we’ll go with:
The work
I’ve spent the last year working across three distinct teams, each working on different (and totally greenfield) products.
Status Pages (Jan-Mar)
The year began with us wanting to launch incident.io’s first ‘new’ product, Status Pages.
In my last post I said:
I’ll be starting 2023 by supporting the creation of a new team, the first we’ll be creating out of the general engineering pool.
In a past life, I’ve found success in joining a team and helping them establish themselves, building relationships that last so I can support them once I move away.
That team was the Status Pages team, and my gameplan for a project like this is joining the team properly for 6-8 weeks, with an aim of:
- Establish a baseline for ways of working (2 weeks)
- Grind to a meaningful goal (2 weeks, repeat 1-2x)
- Repeat (2) but with an eye on succession (2 weeks)
At least, this was how I framed it when planning with Pete…
…and it – broadly – worked, with me joining a team of Martha (TL), Megan (PM), Isaac, Dimitra (eng) and James (designer) to build the MVP of what has eventually become our industry-leading status page offering.
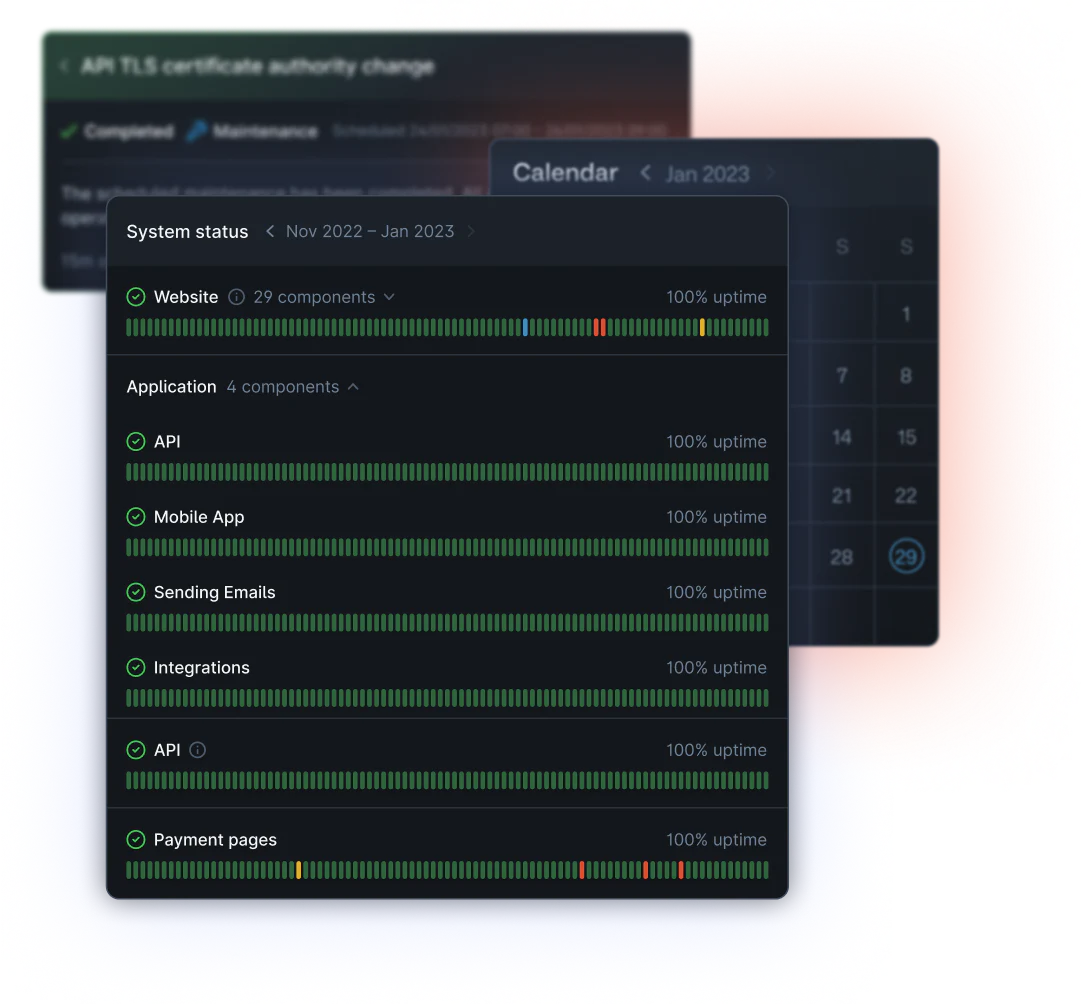
As expected, the first step was figuring out what on earth we would build. It’s easy to assume you ‘know’ what the project will be before you begin but that’s always never the case: what even is a status page, really?
Obviously, you need a page to display the status of your site, but:
- Do we run health checks against customer sites?
- Are we planning on integrating with monitoring tools like Datadog to power uptime charts?
- Will our pages be authenticated?
This was the most difficult part of my time in the team, mostly because having started work on January 1st, there were several key stakeholders out-of-office.
We had assumed a status page was so ‘obvious’ that the team could get on with planning the product without too much outside guidance, but it happens that commercial goals significantly impact what you build in this space (are you building for brand presence, existing customer experience, or revenue generation?).
This caused us to stall, which felt–to the team–like a false start. I’ll be keen to avoid starting projects with similar unresolved questions in future!
What followed was much smoother, though: learning our way around Next.js SSR didn’t take too long, and smart decisions such as using Vercel for hosting meant we got to an MVP very quickly. Our product teams can be extremely productive when given space to execute and a clear goal; after the initial ambiguity was cleared we went from an MVP to a feature-full and polished page in just a couple of months.
The team went on to launch Status Pages in April with me having left in March. While I was sad to have left before we’d properly launched the product, I’ve since been really proud of all the work the team has produced.
Especially considering my contribution is intended to be a solid foundation to build on, I’m particularly happy at how much they innovated in the 8 months after launch. Our Status Pages are now the most powerful on the market, with options for internal or customer-specific pages, best-in-class integration with the rest of our product, authenticated pages and more.
I’m proud to have been there at the start to help them get going!
Catalog (Apr-July)
As I began to look for the next project after Status Pages, it happened that customers kept asking us for ‘something’ that sounded a lot like a service catalog.
This landed on my doorstep, not least because I’ve been thinking about service catalogs for years but also because it’s a product feature I’ve been planning since I joined the company. I’ve already written about my experience of this project in “Three months building a catalog” where I talk about what the work itself looked like, so won’t repeat myself here.
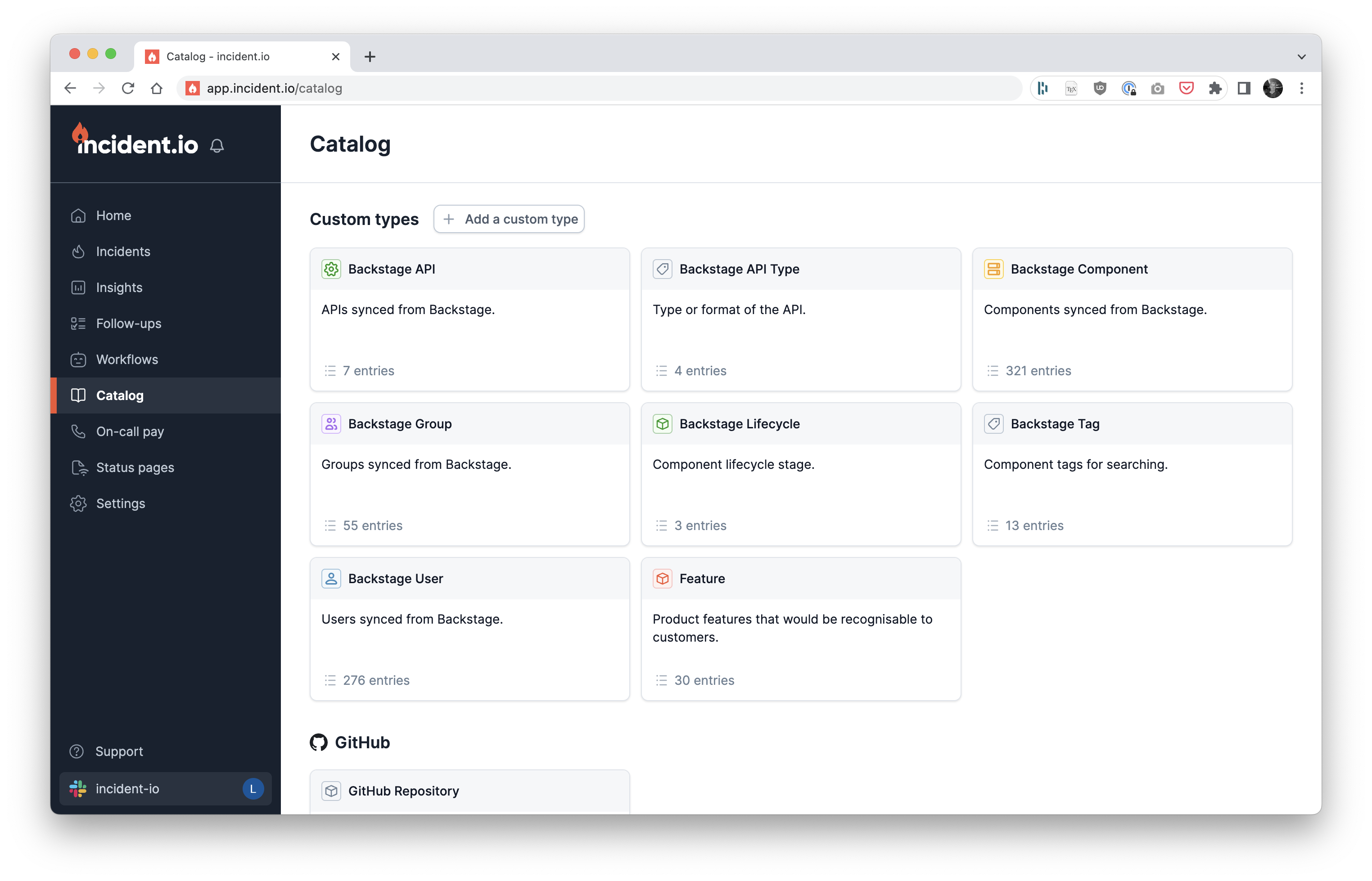
Reflecting on this project from a personal perspective, though, I found the move from Status Pages straight into catalog to be difficult.
I’d left a team (Status Pages) that was just hitting its stride, a team I enjoyed working with, and before the product I’d invested a lot into was launched. It felt like I’d got off one stop too soon, and going straight back into the (extreme) ambiguity of catalog discovery, initially solo, was a big gear shift.
Other aspects made this project hard, too: holidays and conferences came at inopportune times, and it happens that building a catalog–at least, the one we wanted to build–is very technically challenging. Even explaining what you were building to internal teams was a hurdle!
So hard work, but we launched Catalog in June to a massive amount of customer appreciation and surprisingly high adoption. The feedback we heard was our product was much more flexible than our competitors, that it felt great to use, and people were surprised at how many previously impossible or painful automations it made possible.
I stuck around until after launch this time, too, so I left with much more closure than I had Status Pages.
On-call REDACTED (July-Dec)
After catalog launched, I moved to start a team building our most ambitious product yet, one that we’re yet to announce or launch.
So happy to share this project was building incident.io On-call!
You should absolutely check-out the launch video and keep an eye out for a load of technical content I’ve been storing up while this project was under-wraps that I can’t wait to get out in the open.
This project has required the largest amount of up-front design of any project I’ve worked on before, the next largest (in my experience) being adding an Open-Banking payments scheme to the GoCardless product, an undertaking that built into four teams over a 9-month period.
As an initial team of six (PM, TL, designer, 2x SDE, 1x SRE) the first two weeks involved about 6 hours a day of whiteboarding and discussions, producing technical docs to explore different approaches. The process reminded me a lot of Stripe’s designing a unified payments API, with us trying to consider every possible way a customer might want to use this product before we commit to a design.
It was exhausting but a load of fun, and you’d often find the team sitting in odd positions with blank stares after a day of working on it, or producing increasingly unhinged AI photoshops and meeting notes…

After the initial discovery, we got stuck into building.
This is a big project that we’re going to release in one go, which comes with all the usual challenges like motivating the team without a regular “we’ve shipped this!” cadence, or managing the compounding risk of building so much on top of product that customers haven’t yet used.
You can manage these problems: we’ve tried hard to find clear milestones and celebrate hitting them, and we have design partners who are using what we build and giving early feedback. It’s still harder than a normal 2-weeks-then-release cycle though, especially in an organisation like ours that’s built around those faster feedback loops.
It’s awkward talking in abstract about what we’re building but I will say this is something we knew we’d build from the moment I’d joined, and I’ve had it in mind over every project I’ve ever done at incident. If I’ve done my job well, the new product will fit within the rest of our product suite as if it was always designed to be there (because in a sense, it was) and it’s been fun to see which of those anticipatory decisions have paid-off.
I can’t wait until we’ve launched and I can speak about this publicly, but for now…
🤐
Wins
There are a number of things I’d consider a ‘win’ from last year. Here are a few that stood out to me.
Internships
It was very last-minute, but in December we decided to work with Imperial (my old university) to offer three internship placements for the coming summer.
My part in this process was to create a take-home test that we’d use to decide who to bring into the on-site interviews. I always find the process of building these tests fun, and I was especially happy with how this test introduced students to our space (incident response), having them build an on-call scheduler.
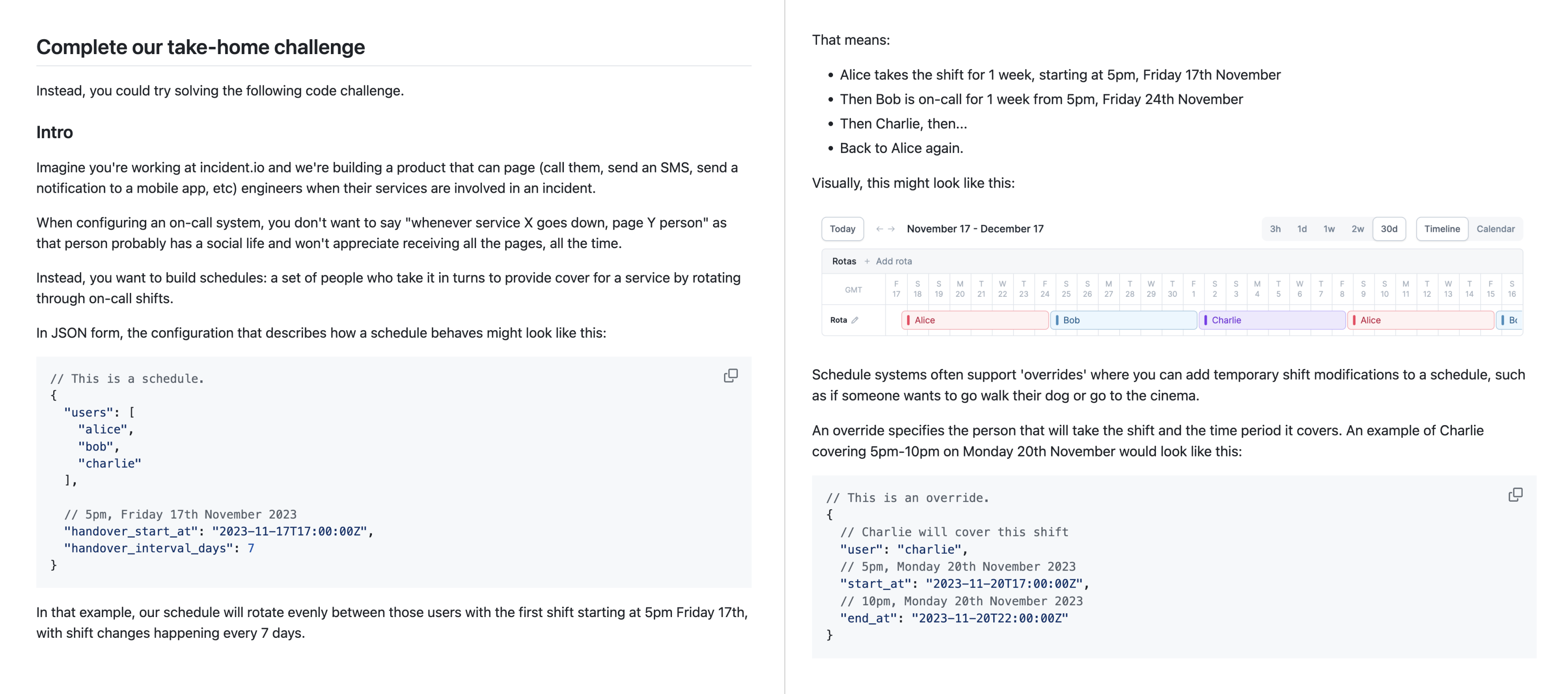
The 20 candidates who passed the take-home came into the office for an assessment day, interviewing with a number of our product team. We ended the day extremely impressed with the quality of the candidates, leading to an intense decision meeting where we had to decide which of the many candidates we wanted to hire would get one of the three places.
This process felt really special to me. I wouldn’t be where I am now had I not done a similar six-month placement at GoCardless, and the idea that some of these students may one day feel the same about incident.io is a great (but weird!) moment.
Migration from Heroku to GCP
Since I joined incident we had run on Heroku. I’m happy to say that’s no longer the case, having migrated ourselves entirely into GCP in September, taking less than 10 minutes of downtime.
I was around on migration day (Saturday) to assist, but full credit for how smoothly this went goes to Ben Wheatley, our (at the time) one-man SRE team.
Ben had spent the weeks in advance of the migration both building out the GCP platform and the migration plan into it. I’ve worked with Ben for years and know how meticulous he is, but I was most impressed with how he worked with the broader Product Engineering team during this process.
For each stage of the migration, Ben found volunteers with an interest in infrastructure to pair with him. Working like this was a great way to build operational experience before we moved over (our Product Engineers are on-call and will need this knowledge) but it also helped incorporate an app engineering perspective, something you can see in the ergonomics of the new tools/processes.
Not only did the migration go fast and smooth, it also showcased a model of SRE <> SDE collaboration that is rare in our industry, one I’d like us to remember and do more of as we grow.
Engineering nits
We try to be pragmatic when it comes to technical investments, accepting that no code is ever ‘perfect’ and trying to avoid implementing ‘best practices’ without asking if they make sense for us first.
It’s easy to join the team and interpret this as “we never make technical investments” which is a terrible outcome for everyone, especially as that’s definitely not our view.
I believe the opposite: that we’re great at making judicious and impactful
technical investments and we’ve been doing so ever since the company was born.
On the hunch that this work is happening but lacked visibility, I created an
#engineering-nits Slack channel to improve things.

If–as an incident developer–you hit a snag or think “urgh, that was annoying” when writing code or using tools, this channel is where you should post your thoughts.
It’s explicitly not about venting, and is instead about building awareness of our weaknesses and highlighting the work people are doing to improve or fix problems alongside normal product delivery.
We’ve since had 10 engineers contribute 30 ‘nits’ to the channel, where we’ve found solutions for 13 of them (45%). Every nit comes with a discussion that shares context and history of the codebase, turning the channel into a great knowledge-sharing tool as well as a demonstration of the investment we do want to prioritise and an example of people doing it.
These nits have ranged from:
- Our hot-reloader is flaky and loading stale code (fixed!)
- Writing ‘deletion protection’ code for the product is difficult (fixed!)
- Deploys are slow (on-going)
- Test output for errors is bad (fixed!)
Anyone is free to discuss or tackle the problems in the channel, and we’ve even started a series of blog posts for people who want to share this type of work externally (see Storybook for Slack and Generating code faster).
At 25 engineers and growing, now is the time to start being deliberate about the culture we want to create. Empowering every developer to own and improve the codebase is a key part of my ideal culture; #engineering-nits is a small but promising step in the right direction.
Observations
General observations that I’ve taken from the year, both general and personal.
AI
I began the year sceptical about AI. Clearly it was becoming an important tool, but I didn’t know how quickly it would find its way into all software, or how that would feel.
After last year’s developments, I now believe AI tools will become a key part of every product team’s toolbelt, and teams who don’t take advantage of them will be leaving a category of delight and product-polish on the table.
I’ve come to this through several experiences, such as:
- My initial experiments using OpenAI APIs to build toy product features back in February.
- Watching how quickly teams at incident adopted these tools, finding new ways to develop with them, such as incorporating real-time feedback from the product into their evaluation of the model.
- Recently using AI for data analysis of developer MacBook build times and was blown away at what it could do.
I’m not yet convinced that AI will take over the world, and I don’t believe this generation of AI tools is going to take our (software engineers) jobs. But I do think you could review any software product and–with minimal effort–use AI tools to improve or totally reimagine those UIs, leading to vastly improved customer experiences.
Just as the DevOps movement brought production operations into the remit of app developers, the ubiquity of AI tools and the potential they unlock will force the average developer to start using them. That’s going to be an interesting shift, given how few developers have experience working with non-deterministic data models or similar systems.
My role
Urgh, this one is hard.
For anyone in similar positions, let me be clear: moving from a Principal/Staff position at a larger (500+) company into a start-up is going to feel pretty confusing.
I’ve had 2.5 years to figure this out but in a company that’s grown this fast–from me joining as first employee to our now 80+ person team–how you interpret your role might change every six months, so you don’t get much time to settle in.
This year started with the creation of the first separate team (Status Pages) and was followed quickly by four more. We’ve built each team from a common leadership structure: Product Manager, Tech Lead, Engineering Manager and (where we have resource) a Design Lead.
You need this structure to encourage the right type of inter-lead-and-team collaboration, but it’s made my job a bit harder: as someone outside that structure but with a role that requires me to work across teams, I have to try a bit harder to make sure I’m involved at the right time. I still find my way into much of what I need to be in and most people know when to pull on me for input, but I miss the clearer structure I’d known at GoCardless where it was more officially understood how I might be useful to people.
On a different note: this year surprised me with how much time I spent actually building.
Most of my time being spent in a team building things has meant a lot of my impact has come from ensuring the product we’re building has ‘multiplicative impact’ where each new product feature makes the whole suite stronger, in a ‘greater than the sum of its parts’ sense.
The best example of this is the Catalog which has become a foundational part of our product, weaving its way into many other product features. The idea of putting your organisation’s data into our tool (via the Catalog) is to allow other features to do things with that data, so it’s unsurprising other features have begun to build on it, but it’s not just about that.
Just as important as if other features start using it is making it easy for teams to do so, providing ‘lego bricks’ through which they can access the abstraction, and ensuring that if you invest in those ‘bricks’ then all other features using them can benefit.
Doing this right would mean Catalog ends up everywhere, which is what we’ve seen:
- Auto-export follow-ups can use Catalog to determine what Jira/Linear Project/Team you export to.
- Introducing status page sub-pages links sub-pages to Catalog data so you can say “create sub-pages for each Region in the Catalog”.
- Configure your debriefs uses the Catalog to determine who to invite to your incident debriefs (e.g. invite the TL + EM + PM of the Teams affected by this incident).
That even ignores much of what we’ve been building for the last 6 months (and is yet to be released) that is built entirely on top of Catalog.
The tl;dr is that this year has been about putting my energy into this type of stewardship, both around the product that we build and the tools that we use to build it. I expect next year will see me do less of this myself and more of working with teams to help them think like this themselves, though it’ll depend a lot on the challenges we face as to where I’m most useful.
Writing
Every year I say I’d like to write more, and each year I write less. No doubt this trend will continue, but I am happy with a few pieces I wrote this year.
Keep the monolith, but split the workloads started a huge online discussion that kept going for a couple of weeks. This is great as the post (1) exhibits a lot of ways we think about software at incident.io and (2) gets us a bit more exposure as a Go shop, which is great for our recruitment efforts.
It’s also a topic I have a lot of experience with and one I’d love to speak about, but am yet to find the right conference for it.
The other big-ticket post was Tracking developer build times to decide if the M3 MacBook is worth upgrading. The investigation and process of writing this post was really enjoyable, and like many of my favourites included a combination of hacking (building the new hot-reloader), technical deep-dive (Go compiler performance) and data analysis. It’s a great example of the ‘fun’ someone might have if they join the incident team.
Personal blog posts are where I get a bit sad: this died a death this year, mostly because I was spending all my efforts building product. There were a few that landed well, though:
- Three months building Catalog (July)
- Use your database to power state machines (September)
- Adding concurrency control to HTTP APIs (October)
Next year I’d love to lean a bit more technical, going deeper on the tools we use at incident and the strategies we’ve taken to evolve the codebase or improve reliability. We’ll see if there’s time for that, amongst everything else!
Brace for impact
That’s it, 2023 is over with.
While it’s been a hell of a year and I’m proud of everything in this post, I confess it feels misrepresentative: the majority has been spent building a product we’re yet to release, so it’s–by necessity–an incomplete picture.
That’s no bad thing, though! It just means a lot of the work this year has gone into making 2024 incredible.
Unsurprisingly, I’m a mix of excited, hopeful, and trepidatious about the next 12 months. I have no doubt it’ll be the biggest year yet in my incident.io career, but I’m finding it harder to predict than the previous two. That’s the nature of us making some big, potentially company-changing bets, but we won’t know if we’ve hit a home run until they land.
I know it’ll be a lot of hard work, but I’m confident we’ll make something great of it. Whatever happens, I’ll be proud to work alongside the amazing team we’ve built, am excited by all the new people we’ll welcome, and will try my best to make sure this is a year we can’t forget.
If you liked this post and want to see more, follow me on LinkedIn.