
Last year I wrote this from an empty office on New Year’s Eve. This year I’m in the boardroom between Christmas and New Year, back from a Pizza Union lunch, waiting for mulled wine to heat up in a Moccamaster because we’re not allowed a saucepan in the kitchen. There’s a handful of engineers half-working, half-chatting in the background. It’s a quiet week.
This is markedly better than last year.
In 2024 I said I expected to be “wrestling with AI” for another year. I was right. It was worth it.
- The bet (January–March)
- The push (April–September)
- The product (October–December)
- The team
- Everything else
- The hardest year
- Looking ahead
Preread
For those fortunate enough to have avoided my internet presence, I’m a founding engineer at incident.io leading the AI team. My last year has been about building an ‘AI SRE’: a system that can debug production incidents for you, digging through logs, metrics, traces and historic incidents to tell you what’s gone wrong and how to fix it.
In this post I’ll talk about the ‘investigation system’ which is what does the debugging of incidents, and chats back to responders in their incident channel. I’ll also mention the @incident chatbot which responders can ask to take actions on their behalf or use to query things “what’s the error rate right now? does this support our theory that service X is the cause?”
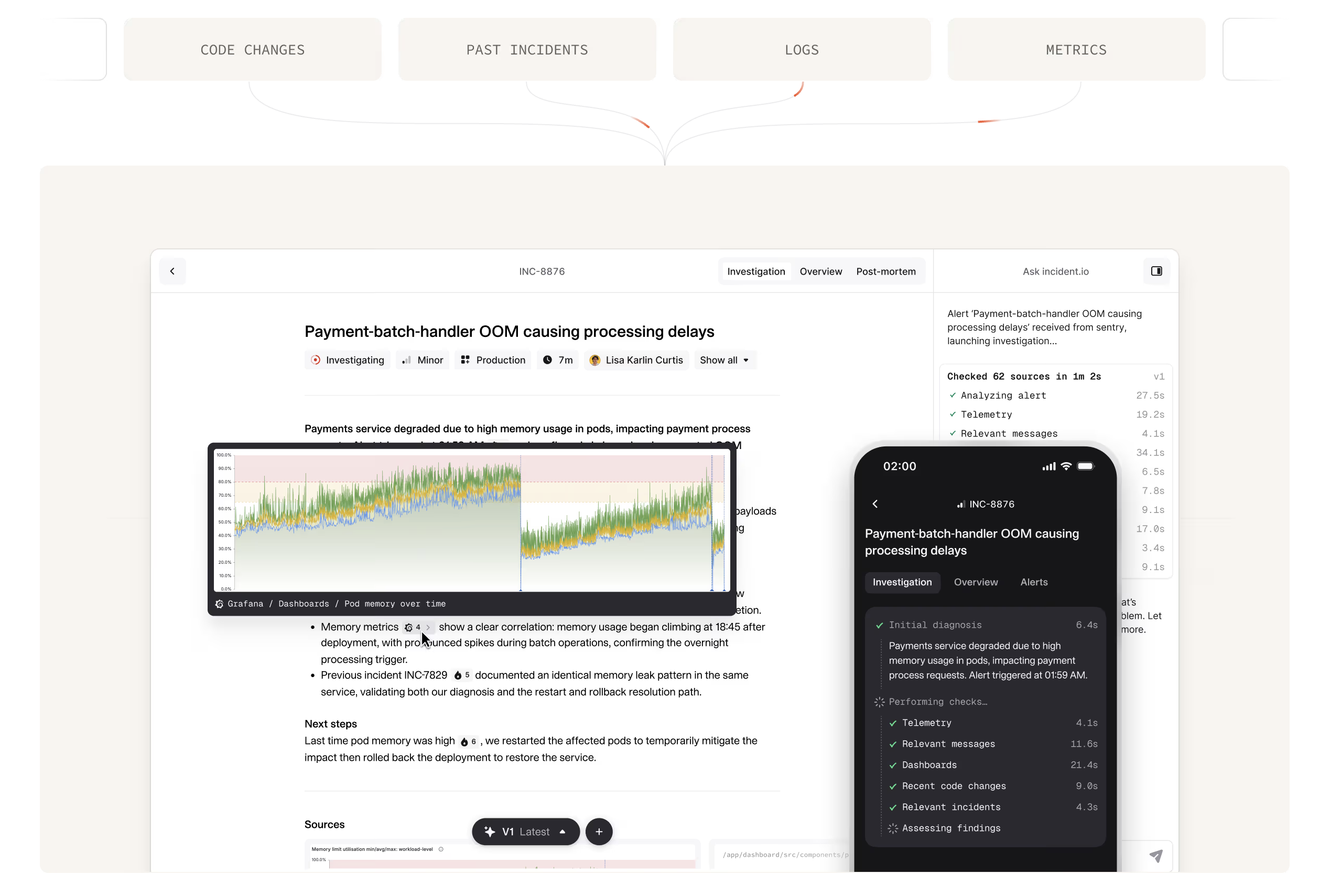
That should be enough about the product to understand, and some contextual markers for the company are:
- Grew from 69 → 160 people, 20 → 45 in engineering
- Substantially grew revenue
- Series B in April: $62M at $400M valuation
And with that…
The bet (January–March)
Coming back from Christmas, the investigation system (what triggers at the start of an incident and tries to diagnose the issue) was working in a “prototype way”.
It could search for code changes, relevant Slack messages, past incidents, but making improvements was hard. At ~50 prompts all interacting with one another it was too easy to make a change in one place that broke the system elsewhere, and with only prompt-level evals (essentially unit tests) we didn’t have enough safeguards to allow scaling the team in headcount.
I’d spent the previous December making ad-hoc changes and hoping they’d work, but I was sorely missing tools that could quickly confirm the impact was good or catch if there were regressions. With us making a big bet on AI–the Series B already in motion–it wasn’t viable for just me to be working on this.
What that meant was a bit uncertain, as ‘tooling’ for AI systems was fairly nascent at the time. Pulling nouns out of thin air, I’d arrived at this idea of building ‘datasets’ that we could ‘backtest’ AI interactions against, with ‘graders’ that could score the interactions and ‘scorecards’ to track in which direction the scores moved.
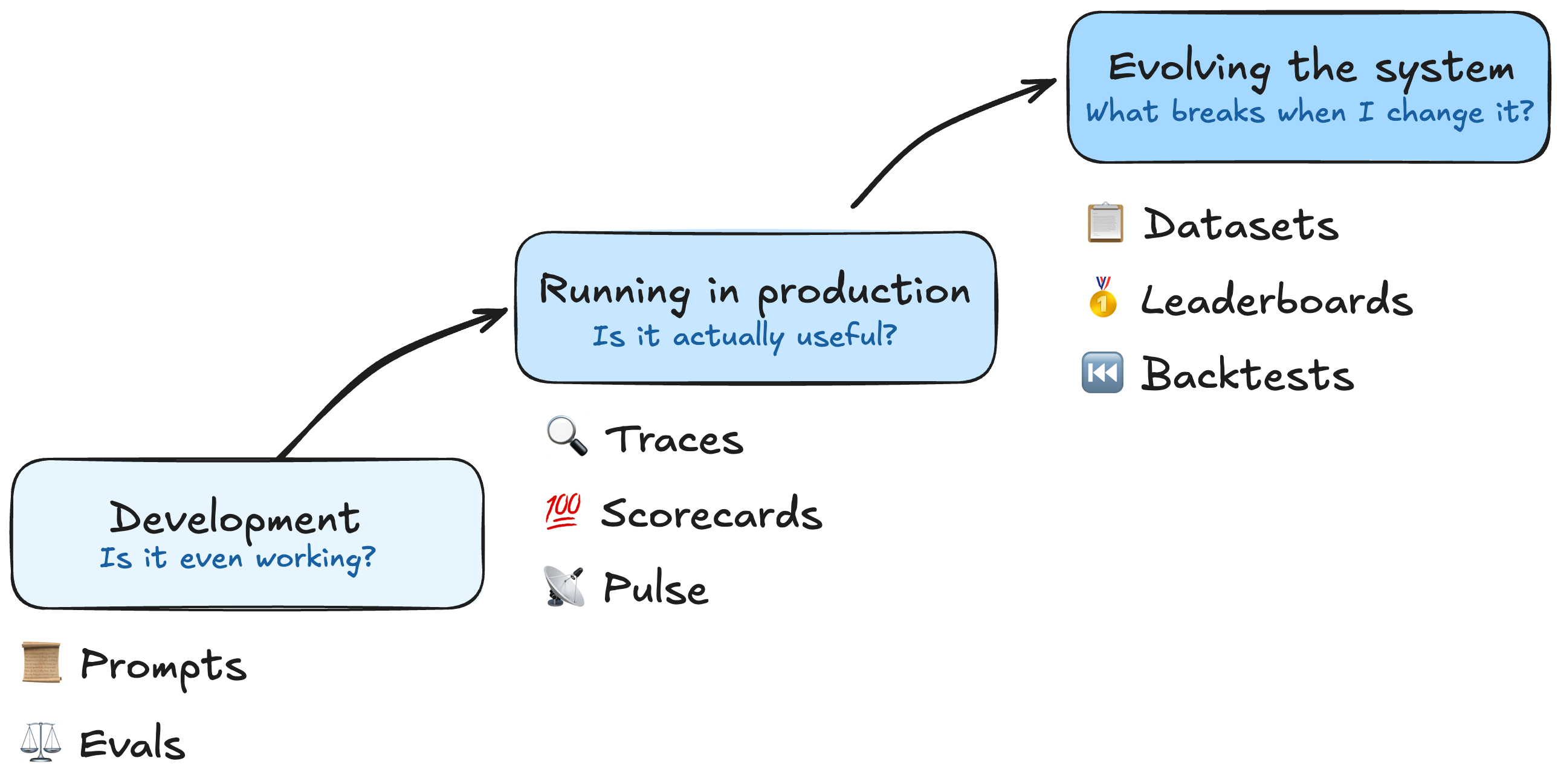
I spoke about the AI ‘maturity’ scale at LDX3 later that year, which is what I spent January building. While uncomfortable pausing work on the actual product, it was a ‘slow-down to speed-up’ investment which I hoped would unlock more people being able to work on the investigation system in parallel.
The breakthrough moment came quicker than I expected, where the MVP backtest system helped make a change to PR searcher that meant in just an hour I improved precision and recall by ~20% and could prove that my change was responsible. It may not sound like much, but until now the changes we’d make were mostly intuitive, making tweaks that made sense theoretically but lacking the “it made this number go up!”. It was a deep relief to unlock a more robust workflow, and we immediately got Lisa and Rory involved in tuning the system.
Honestly though, a lot of this AI work is just making things up. There aren’t any great systems for building complex GenAI products because until now those products haven’t existed, so figuring out sensible approaches to testing and scaling a team was about taking approaches from other disciplines and refitting them to work for this new world.
Consequently, I was a bit nervous. Especially going into the Series B process when I was being interviewed by potential investors on how we’re building the AI product, it was very possible they’d laugh at how naive our approach was.
Happily, that turned out not to be the case! I must’ve spoken to tens of companies and experts familiar with AI development and felt pretty happy that every one of them was surprised at our level of sophistication. We had a system that was extremely non-deterministic, solving complex problems with multiple agents interacting, but we’d got to a place where changes could be made with confidence leaning on measurements we could trust. Apparently this was exceedingly rare.

We continued to hill-climb on the investigation scores and improve our tooling, eventually taking a few days as a team to write-up a lot of what we’d learned, turning it into our Building with AI microsite alongside a feature in The Pragmatic Engineer. The whole team contributed, which felt like a good celebration of what we’d achieved, especially as the product itself wasn’t live with customers (which is usually where our team gets their buzz).
The bet on tooling paid off, and continues to. At this point it unlocked adding more people, but has since allowed us to substantially scale-out AI in the company.
And then we announced the Series B. And then we picked a date.
The push (April–September)
In late May we had the full company offsite in Greece - our first with half the company in the US and half in the UK. On the last day, tired after a lot of fun, I sat down with founder and leadership and for the first time seriously spoke about: what are we going to release? When do we show it? What do we actually demo?
At that point we had the investigation system (sometimes good, sometimes not) automated suggestions into channels, the chatbot for updates and questions. But nothing tied together into a cohesive product. This was a result of AI being so R&D heavy, where you don’t know what you’re going to build until you build it and see what works. So there was a lot of work before this felt like a real ‘product’.
We decided to target Sev0 San Francisco in September. It’s our yearly conference in our flagship city, and felt an appropriate moment to release AI SRE to the world properly.
The scope we landed on was ambitious: a fully live demo where nothing was faked. Trigger a real incident in our own production, get paged, kick off the investigation, let it find the causing PR, draft a fix, merge it, interact with the chatbot, build a post-mortem. The whole flow, live, in front of hundreds of people.
That meant we needed to get from “80% of the time it works” to “100% for a live demo.” That’s a big gap.
It was in August that we had a sit-down with the AI team and properly acknowledged how large that gap was. Given the importance of Sev0, we were looking for levers that could make sure we hit an amazing result, having already pulled most of them.
In a time like this, where you have a huge amount of work to do and a deadline to hit, the most reliable option is (unfortunately) just working more. Any arrangement like this is a two-way street and the company is required to support the team too: food in the office, overtime pay, taxi expenses, removal from interviews and other lower priority meetings. None of it was mandatory, but the importance of us nailing this was made clear.
I was nervous about this ask. The team were already working hard and we’d just added several new people - asking them to ramp up into a crunch felt tough, but the response was overwhelmingly positive. I was shocked at how it galvanised the team which was maybe a bit naive of me. This opportunity is really huge and that was obvious to me, and unsurprisingly the team around me felt the same. Not only that, but having the company expressly clear out any distractions or red tape and allow you to focus on work that really excites you, well. Apparently that’s something that resonates here.
We moved into a room at the end of the office - new desks, whiteboards on the walls, windows overlooking a park. Rory jokingly called it the “Swedish prison” (“still a prison, but quite nice”). I actively discouraged this but lost the battle when someone installed a flag.

The ‘crunch’ began with ‘the great refactor’. We’d been building all sorts of AI
features in a quick experimentation loop, but that meant the ideal structure of
the codebase was something we’d deferred, leading to the majority of our AI code
living in a single Go package called copilot with 500 files.
The team growing from ~3 to ~7 engineers, a package like that no longer works,
as the blast radius modifying a single file is much harder to predict with
everything tangled together. Merge conflicts are a horrible way to live, and
ownership is hard in a setting like this (not to mention onboarding) so over
July and August we restructured everything into an organised app/ai/*
hierarchy with 25+ packages. It was a lot to do simultaneously with the Sev0
push, but it’s what enabled us to scale the team without everything falling
over.
Leading up-to Sev0 the daily rhythm was: stand-ups covering each of the several on-going projects, and daily demo dry-runs with Pete where we’d build a friction log of everything that needed improvement. That would produce a backlog, then subgroups of 2-3 engineers would own a focus area and work from the backlog, holding themselves to account with backtests and scores. If we started with 80% correctness when querying the catalog, for example, that subgroup would own bringing it to 100% before we went out on stage.
You could see it getting better day by day, which was motivating.
Some of the debugging got strange. I remember testing whether the chatbot could see images as they were passed between LLM tool calls. You want to use novel pictures each time to avoid the LLM ‘cheating’ by reading your previous interactions and tricking you into thinking it was working.
At that point, working many hours a day late into the evening, you all end up in fits of giggles laughing at how ridiculous your job has become. The image of everyone tired in a room late at night, laughing at the absurdity of copying dog pictures into incident channels, that’s what engineering looked like this year.

The demo at Sev0 SF went really, really well. Pete showed the live demo, then I did a ‘behind the scenes’ segment walking through the same investigation but showing our internal tooling - how we actually trust and evolve the system. Over 4.5 minutes, watching it go through all the investigation steps and arrive at conclusions about what the problem was. All of it worked. We were over the moon.
The audience included people from Amazon, Anthropic, Databricks, Docker, Etsy, Netflix, Uber. The feedback was overwhelming: “this is exactly what we want.”
We delivered exactly what we’d committed to at the offsite - that last day in Greece when we said Sev0 September is when we release this. It felt like we did a phenomenal job given all the constraints.
Afterwards, jet-lagged and exhausted, Martha, Rory, Shlok, Sam, Ed bumbled around San Francisco with me. We hiked Eagles Point. Tried to see the sea lions - they stunk. Attempted a baseball game but messed-up the timings. Scootered between drinks. Really fun, really exhausting, really worthwhile.
One moment I keep coming back to: Shlok joined as an intern during the craziest time, got onboarded onto all the AI stuff, contributed to the Sev0 demo, came to San Francisco, and saw his work presented on stage. As someone who wouldn’t be here if not for my internship at GoCardless, seeing the company grow into a place that can give that type of experience is quite emotional.
They say there are different types of fun, where ‘Type 2’ is challenges that become rewarding in retrospect. I’ve had a lot of that in my career, enough that I’ve become good at recognising when it’s happening at the time and appreciating it.
Perhaps that’s cheating, but I realised how much I’d miss it even when locked in the Swedish prison. Lots of memories.
The product (October–December)
For about 12 months I’d been telling Pete that we should hold off on telemetry (metrics, logs, traces).
My theory was that competitors were going deep on observability because they don’t have incident data. We do. Our platform is the system of record for everything that happens during incident response - alerts, code changes, postmortems, Slack messages. That’s data no one else has, and I thought we should exhaust what we could do with it before chasing telemetry connections.
I was increasingly uncomfortable with this position. As time went on and competitors invested heavily in their observability integrations, I started to feel like I was wrong. But we kept pushing on the investigation brain - what we call the ‘assessment’ step - modelling chains of causation, structuring findings more robustly, introducing thinking models in various places.
In November, something clicked. The changes we’d made drove our RCA quality scores from ~60% to 75-80%. At that point, the feedback from customers changed: “This is really good. I just want you to have access to more data. It’s not that your reasoning is wrong - it’s that you can’t see the logs.”
Now it made sense to start on telemetry.
The good thing about having held off is that I’d been thinking about the architecture for almost a year. I sat down and realised we could build this out really quickly. What followed was about four weeks of me trying to spike out a system that could plug into any data source - logs, metrics, dashboards, traces, even SQL databases - and expose them behind a ‘telemetry agent’ that understands how to use them.
One driving principle of all our AI SRE so far has been to make it work generally, without requiring customers to give specific instructions or customise the prompts. Telemetry should be the same: you plug in a data source, the system compiles information about what’s in there, combines it with a language specification for how to query it, and learns how to use it effectively. When an incident happens, it already knows what data is available and how to get at it. Zero custom prompting per customer - it generically understands how to use their systems.
After building the initial telemetry system with Loki + Prometheus + Tempo, the team managed to get Datadog (logs, metrics and traces) up and running in just a week. When we dialled it in for one of our design partners, it took two hours to fix-up some teething problems and see their investigation scores jump.
The results have been kind of incredible. The team’s Slack is now full of messages like:
- “It beat me by about 6 hours” - on finding a foreign key constraint violation from logs
- “There was no dashboard for this, it just found it” - on a batch job that silently stopped running
- “Do you know how hard it’d be to find that in a trace on mobile?” - on finding a date bug where the iOS app requested schedule entries for year 2061
- “The fact that it’s able to validate this is fucking insane”
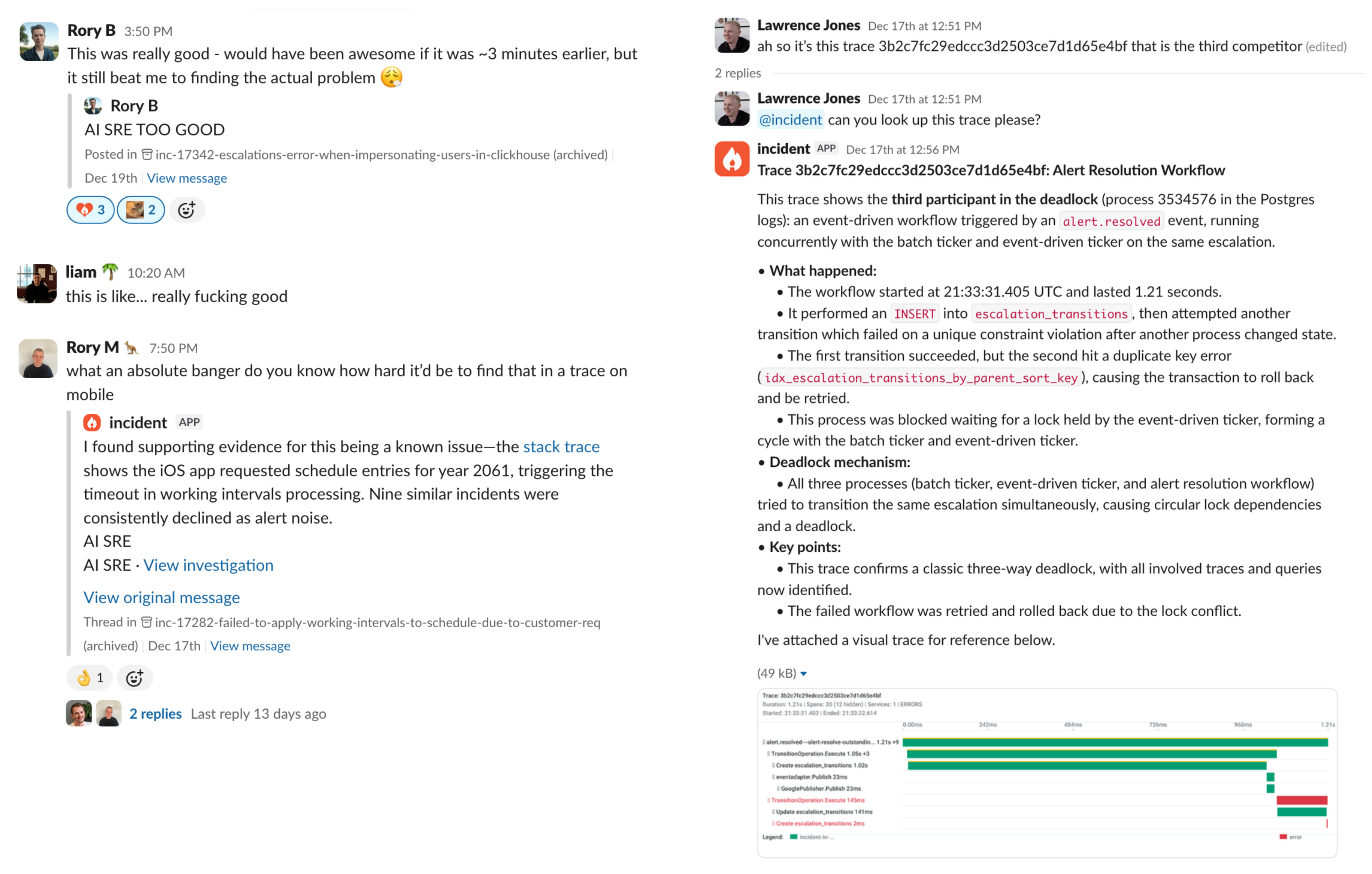
In our production incident account, we now have AI SRE connected to Grafana (Loki, Prometheus, Tempo), GCP logs, dashboards, and more. When our Cloud SQL has a deadlock, it correlates the alert logs with deadlock logs and lock wait lists from cloud logging. It’s able to combine these sources into a picture that’s more complete than anything we’ve had before.
Honestly, I use the telemetry agent more than I use Grafana now. It’s better than me at formulating the right LogQL or PromQL query, and being able to tie that immediately into GCP cloud logging - then feed it back into the investigation to refine what we think is going wrong - that’s game-changingly good.
By December we’d hit ~90% RCA quality across 50 representative incidents. Design partners are starting to say “this is seriously useful” and our job over the next couple of months is to get them to “I cannot live without this.”
Reflecting on this: I think I’ve been messing around with how to build these kinds of abstractions for most of my professional career. pgsink (an open source ETL project I built years ago), the alert system abstractions at incident.io, the engine programming language that powers our conditional logic. Building systems like this is my biggest strength as an engineer, and I’m really excited about what this framework will allow us to do.
It’s made me feel better about holding off as long as we did, now we can see how fast we can build on stronger foundations.
The team
In January, the AI team was me, Lisa, and Rory Malcolm. By December, we were 18 engineers.
Growing a team 6x while shipping a product is hard. Growing an AI team 6x is harder, because AI work doesn’t fit normal frameworks.
You can’t scope it in advance - you’re often trying to do something you’re not sure will work, so you prototype until something emerges. And our normal processes like ‘polish parties’, where you walk through the product click-by-click and roast the flow, fall short because AI might work for one use case and fail terribly for 30% of others. If you created a pretty AI interaction where the AI is totally wrong, no one cares. It might even offend them more.
What worked instead was what I described in the push: subgroups owning specific parts of the system, measured by scores, with full autonomy on how they hit 100%. The eval infrastructure we built in January made this possible, and without it, we couldn’t have parallelised the work.
By December the team had settled into three themes: the ‘brain’ (the core investigation engine), integrations (Datadog, external status pages, IDE distribution), and design partners (proving AI SRE at scale with companies that have thousands of engineers and services).
But broader than just the AI team, there are some moments I keep coming back to:
QCon in April
I was there to support Martha and Alicia who were both giving talks.
QCon is extremely technical - most speakers have published respected technical books. Martha’s talk was about the reliability work we’d done together on the on-call product the previous year: load testing, production drills, all the things I’d learned as an SRE at GoCardless. She’d never done this kind of work before, but she learned it and delivered a talk that was incredibly practical and full of hard-earned lessons.
On-call has averaged four nines availability since launch, which is notable for a product that’s only a year old and already a third of our business. Watching her on stage, I kept thinking about the fact that I joined this company when it was just the three founders, Lisa and I. Now it’s 160 people, and we have engineers speaking at conferences like QCon with authority and confidence.
Anthropic dinner (and others)
I went to an Anthropic engineering leadership dinner in November with a collection of other top company leaders in London.
I’d accepted last minute and hadn’t clocked it was a fancy place in Mayfair - I turned up in a scruffy t-shirt and jeans, looking extremely out of place.
Despite this, it was a real pinch-me moment as people noticed my incident.io namebadge (misspelled, if I remember correctly) and were effusive about our brand and what they’d seen of it. We keep getting comments about being the place to work in London which is a proud moment for everyone who’s helped build the culture here, but it was particularly noticeable in a room full of such high profile companies.
100% offer acceptance
I’m overjoyed that we went all-in on internships and graduate roles this year and have made offers to 5 of each, with all 10 offers being accepted.
That’s crazy in any circumstance but is even wilder considering we had thousands of applicants to both roles. The candidates are the best in the entire country with every company to pick from, but a huge effort to run an exceptional recruitment process has meant they’ve chosen incident.io as the place they’ll start their careers.
It’s not just junior roles, though: we’ve hired about 20 engineers this last year, and the new hires we’ve made are all exceptional. This is the strongest team I’ve ever worked in, full of kind, hard-working and talented people who make working here a joy.
Everything else
Beyond the product work, I’ve been busier externally than any year before. A quick round-up:
Talks
- LeadDev LDX3 (June) - “Becoming AI Engineers” - my first big conference talk, covering maturity stages, tooling, and the human side of AI systems
- Sev0 SF & London (September/October) - “Behind the scenes” product showcase segment
Podcasts
I’ve been doing more podcasts this year, trying to speak about AI and topics on engineering culture.
- AI Adoption Playbook (May) - Building AI that investigates outages, scorecard-driven development
- Adventures in DevOps (October) - Ephemeral runbooks, dynamically generated from PRs and past incidents
- IT Visionaries (November) - “90% of AI Demos Fail” - the gap between demos and production
- Product Talk with Teresa Torres (November) - “When AI Becomes Your SRE” - with Ed Dean
Writing
As is tradition, I’ve done much less writing this year than I would like, but am very proud of our AI microsite and featuring in the Pragmatic Engineer.
- Beyond the AI MVP (February) - What it really takes to ship AI products
- You Don’t Need Python (February) - Building AI in Go, why static typing helps
- AI Innovator’s Dilemma (March) - Why startups have an advantage in AI
- Why Change Role to AI Engineering (April) - Career pivot, what the role actually means
- Plus the Pragmatic Engineer feature and Building with AI microsite launch in March
The hardest year
I’ve worked a lot this year. More than any year before, in this role or otherwise, by a margin. I’m not complaining - I knew what I was signing up for joining a start-up like this – but I want to be honest about the experience instead of pretending it was an easy ride.
AI work doesn’t fit the normal frameworks. You can’t scope it properly because you don’t know what’s going to work until you try it. That makes it hard to forecast, hard to communicate to stakeholders, hard to give PMs and designers something to work with. For long stretches I’d go heads-down building something that might not pan out, then surface weeks later with a prototype and realise I’d left other fires to burn in my absence.
That oscillation is challenging. And the competition hasn’t made it easier - everyone and their grandmother is building an AI SRE nowadays, from well-funded startups to megacap companies like Datadog. There were periods where I genuinely wasn’t sure if we were ahead or behind, and I felt a large amount of responsibility for making sure we landed.
I think what made it manageable was having something to show for it. The Sev0 push was brutal, but we shipped. The telemetry work was intense, but customers are now saying things that make it feel worthwhile. If I’d worked this hard and we’d shipped something mediocre, I’d be in a different headspace right now.
Did I manage it better than 2024? Honestly, yes. Last year I was wrestling with whether AI would work at all. This year I was wrestling with how to make it great. That’s a better problem to have, even if it’s still hard.
The team helped. Having people around who are just as invested, who you can laugh with at 10pm in the Swedish prison while debugging whether an LLM can see a picture of a dog - that makes the difference between miserable and memorable.
Looking ahead
No one has quite cracked AI SRE yet. I think we’ve almost done that.
We have 5 design partners - multi-billion dollar companies with thousands of engineers - running real incidents through AI SRE. We’re at ~90% RCA quality. The telemetry system is working. The team is 18 engineers with a clear path to growing further.
Next year is when the rubber hits the road: actually deploying and selling this at scale. That’s a different kind of challenge to what we’ve faced so far. Less R&D uncertainty, more execution against a defined product. Scaling what works rather than building from scratch.
I don’t think we’ll have the same intensity as this year. Not because we’ll work less, but because the shape of the work changes. The foundation is there now and what comes next is capitalising on that, and if our design partners continue saying what they’re saying, we might have lightning in a bottle.
I’m again reminding myself to be appreciative of the journey. Each year at incident.io has been the most significant and exciting of my career, and that continues. I got to build something genuinely new this year with people I really like working with, and that’s not something to take for granted.
If you’d told me in January where we’d be by December - the product, the team, the external recognition - I’d have been sceptical, but we delivered on almost everything we set out to do.
So what’s the prediction for 2026? We’ll know by this time next year whether AI SRE is truly the product that changes how companies run incidents. I think it will be. And if I’m wrong, it won’t be for lack of trying.
See you then.
If you liked this post and want to see more, follow me on LinkedIn.