
Most companies building AI products today are stuck in the experimental phase, lacking the basic tooling and infrastructure needed to build reliable systems. It’s easy to spot once you know what to look for.
Take the current trend of companies talking about load-balancing their AI operations across multiple providers. Sounds sophisticated, right? But it reveals something concerning about the state of AI engineering.
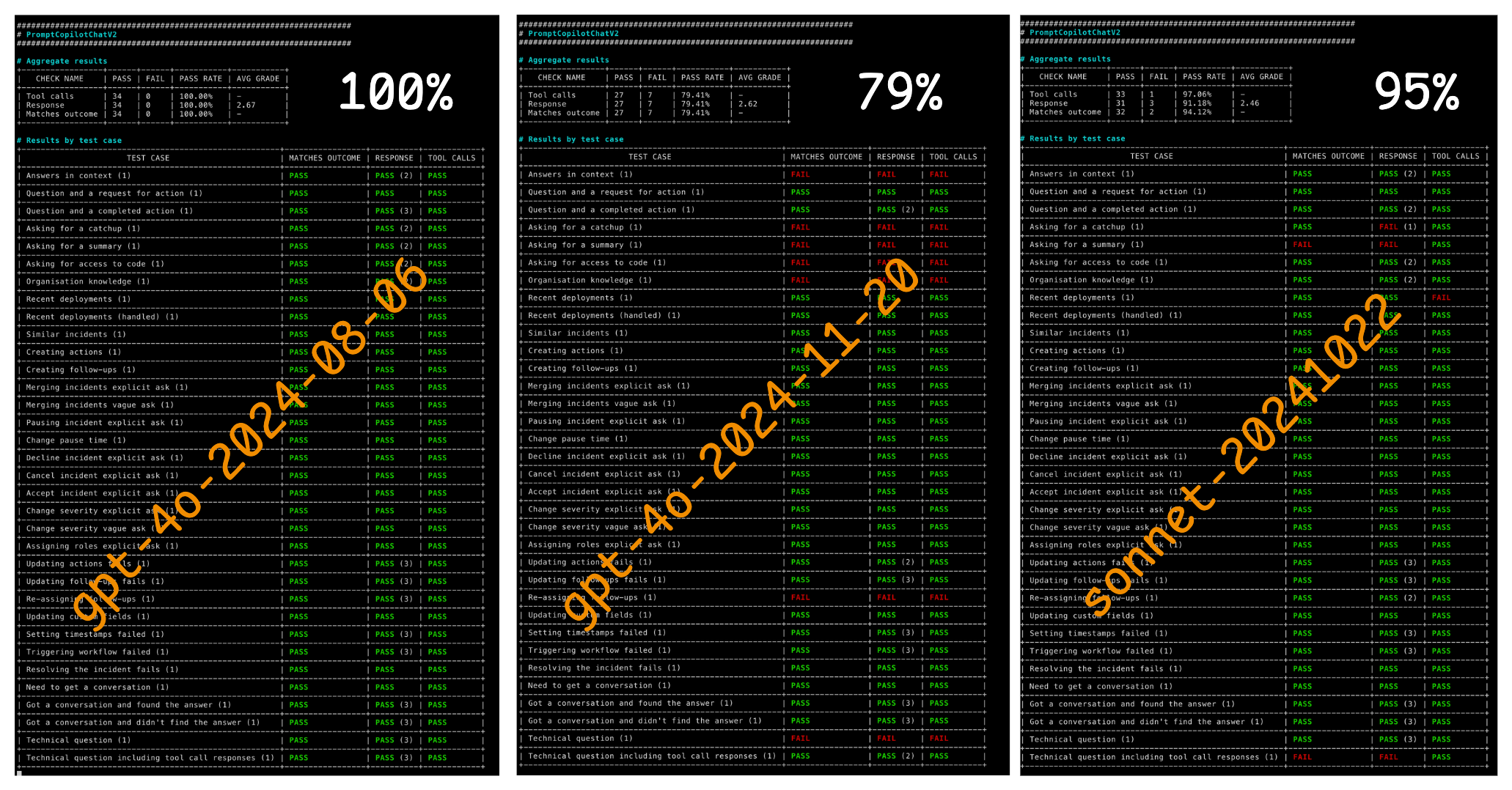
Let me show you why. Last week we tried upgrading from 4o-2024-08-06 to 2024-11-20. Same model, just updated knowledge and weights. On one of our core prompts:
- 4o-2024-08-06 passed 100% of our tests
- 4o-2024-11-20? Dropped to 79%
- And here’s the kicker: Anthropic’s Sonnet 3.5 hit 95%
That last bit is shocking - a completely different model family performed more consistently than an upgraded version of the same model. But what’s more concerning is how many companies are talking about switching between providers, implying they don’t have the tools they need to measure these differences.
This may sound like an easy problem to fix: they can just add tests, right? Sadly this is a lot harder than you might expect, and the gap between “we should test our AI” and having reliable, production-grade evaluation tools is much bigger than people realise, even though it’s essential to building great AI products.
All you need is…
The AI community loves a good “all you need is X”. All you need is attention! All you need is transformers! And the latest: all you need is evals!
Just write some tests, they say. Measure your model performance. Track your metrics. They’re not wrong - but anyone who’s actually tried to build robust testing infrastructure for AI systems knows it’s not that simple.
We’ve got to a place where we can quantify how a model upgrade impacts us, but what have we needed to build to do this?
Well:
- A test suite with 30+ distinct scenarios
- Code to compare expected vs actual outputs (which uses AI, too!)
- The test runner itself
- Strategies to run those tests in our CI without costs spiraling
Honestly, writing the tests themselves is the easy bit! Almost all AI tools and frameworks are written in Python, reflecting the origins of AI in the research teams who built the models and the machine-learning community who first adopted them.
But most product teams don’t use Python, which means you need to create a lot of these tools from scratch. That’s big undertaking, and almost no one is talking about how to integrate this stuff into a normal software development lifecycle.
There’s a reason no one is talking about this: it’s because most teams, even those at billion-dollar companies, just haven’t built this yet.
The AI MVP trap
At incident.io, we wanted to create an automated system for triaging incidents - something that could look at dashboards, merged PRs, and various data sources to figure out what went wrong. Two days later, I had a working prototype that looked amazing. It analysed everything, drew conclusions, and posted them right to our incident channel.
It looked finished. It wasn’t even close.
This is the trap of AI products, and most teams will follow the same pattern.
Let me break it down:
Stage 1: The Deceptive MVP
You build something in days that looks almost finished. The demo is incredible. Your team is excited. Then it meets reality, and everything falls apart. The system that looked so polished in demos starts making basic mistakes that seem obvious in hindsight.
Stage 2: Swings and Non-Deterministic Roundabouts
You start iterating on your MVP, trying to improve it. But as you add complexity, the system becomes increasingly unpredictable. You’re making changes based on vibes, improving some edge cases while (invisibly) breaking others.
This is the stage 90% of companies building AI are in. You can even see it in FANG: the AI features Google have added to GCP feel very much like an engineers first attempt to use an LLM in a product, spitting out terrible SQL suggestions in BigQuery. Apple’s message summarisation features cross-pollinating between messages and providing horribly inaccurate headlines is another.
Stage 3: Science
At this point you realise your system is complex enough that it demands tooling to help manage and understand it, tooling that you need to build. I call this the point at which you need to start to ‘science’ it, taking inspiration from ML practices and finding ways to apply those lessons to your context.
At minimum, you will need:
- An eval test suite
- Automated grading of AI interactions in your product
- Observability tools to help introspect multi-stage LLM interactions
That’s what you need, but you’ll want much more too.
We’ve evolved our tools by (purposely) being intolerant of friction: if you regularly need to do X to work with/debug our AI systems, then we build tooling that makes it cheap for you to do X in minutes.
As one example: it takes less than 30 seconds for an incident.io engineer to go from a failing LLM interaction in production to running it as an eval test case in their IDE. That’s how you build the leverage you need to work with these systems.
Stage 4: Real Work
Finally, you reach a point where you can reliably assess AI performance and improve your system with confidence. You have continuous monitoring, comprehensive eval suites, prompt analysis tools - the works.
And that’s when the uncomfortable truth hits you: everything before this was basically pretending. You look at your tooling, think about how much work it took to get here, and realise something concerning: you haven’t heard many other companies talk about building these kinds of tools.
Which makes you wonder: how many companies are still stuck in that chaotic MVP stage, shipping AI features without really understanding how they’re performing?
It’s not easy, or simple.
Here’s the thing: building reliable AI systems is hard. Really hard. And anyone telling you “all you need is X” is selling you a simplified version of reality. The tools are immature, there aren’t many examples to follow, and if you’re struggling to get things right - that’s completely normal. You’re not alone.
The industry itself is still finding its feet. The first book on “AI Engineering” was literally published last month, and we’re still inventing the terminology to describe what we’re doing. When you’re pushing into new territory like this, it’s critical to understand where your team sits on the maturity curve. Are you still in the MVP stage? Starting to science it? Having a clear picture of where you are helps you mature faster, providing a path forward.
The companies that will succeed with AI won’t be the ones with the biggest budgets, access to the latest models, or even the most ML expertise. They’ll be the ones that invest in understanding their systems, that build the tools to measure and improve them, and that take the time to do things right.
So the next time someone tells you they’re building a multi-provider AI strategy, ask them how they’re measuring the impact. Ask them about their tooling. Ask them about their eval suite. Because if they can’t answer those questions, they’re probably still stuck in the MVP trap - and they might not even know it.
If you liked this post and want to see more, follow me on LinkedIn.