
For the last three months I’ve been working on a team building the incident.io Catalog: read the announcement post here.
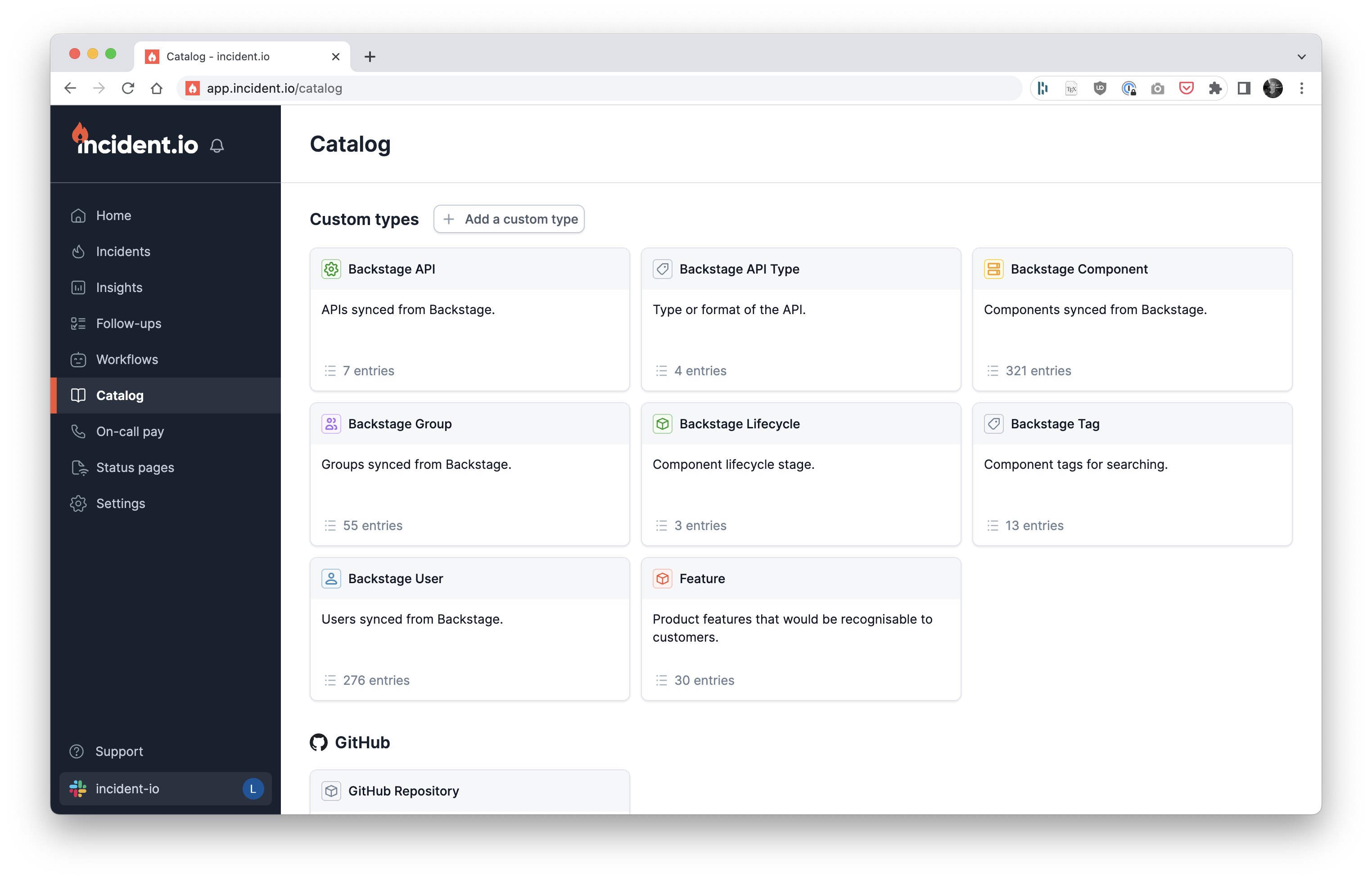
One of the things I enjoy about working at incident is we often build products I’ve been thinking about or actively using for years. The catalog may be the best example of this, having spent years at GoCardless building and looking after our homegrown service registry, and talking publicly about why everyone needs one.
That said, when I was first asked to look into what a catalog would mean for incident, it felt more stressful than exciting. I’ve spoken with loads of companies over the years who have tried implementing a catalog, and it doesn’t make for pretty reading. Many invest heavily only to end up with a token ‘catalog’ that’s mostly vanity, unused by much of the organisation but too embarrassing to now remove.
I was sincerely worried we might build a product of similar anti-value.
Thankfully with what we released today, I can confidently say we haven’t. The catalog we’ve built is woven into our incident product and having dogfooded it ourselves, totally changed our incident response.
There are several decisions we made that lead to this.
Make sure we know why
Our competitors have a catalog already, and we’d often receive requests to build one. But having a catalog is not the end goal, and just ‘building one’ is likely to result in a product that looks pretty and doesn’t help anyone.
Early on, the framing was “if we know about your organisation, we can better help you respond to incidents”.
One example would be “who should I page if this feature is broken?”. This is a common problem customers experienced, and were solving by creating workflows like “when feature is Payment Gateway escalate to Payments team”.
That sucks, because now you have hundreds of workflows for each team. Not manageable, not understandable, and boring to configure. Additionally, if we know about your organisation – such as what product features you manage, and who owns said features – we should be able to build a general “Escalate” workflow that can figure out who to page from whichever features are impacted.
Supercharging your incident response by better understanding your organisation, where that understanding comes from the data you push into the catalog, was our goal.
Bring your schema
So we need to model organisation data in our system. But what model should we use?
To decide, we need to understand how people normally store their data. Our customers generally split into:
- They have nothing: usually a spreadsheet or a document detailing teams and ownership, nothing complex but they often want something more sophisticated.
- There’s a homegrown catalog (like the one I’ve written about at GoCardless) that has already received substantial investment and the organisation is tightly coupled to.
- Using an existing catalog like OpsLevel, Cortex or Backstage. Adoption of these tools is highly variable, ranging from “I think we have it?” to “company-wide mandate that everything goes into Backstage”.
So, like, no consistency. Not even at all.
But that’s ok, because one of my core beliefs about service catalogs is that there is no one-size-fits-all structure that works for everyone. The companies I’ve seen have great success adopting catalogs are often using tools that support very flexible structures, allowing them to easily model their organisation’s weirdness and ease adopting manual existing processes into their catalog.
In contrast, I’ve seen many people stumble trying to adjust their view of the world to the Backstage systems model. Sometimes enough that they give up on the idea of a catalog entirely.
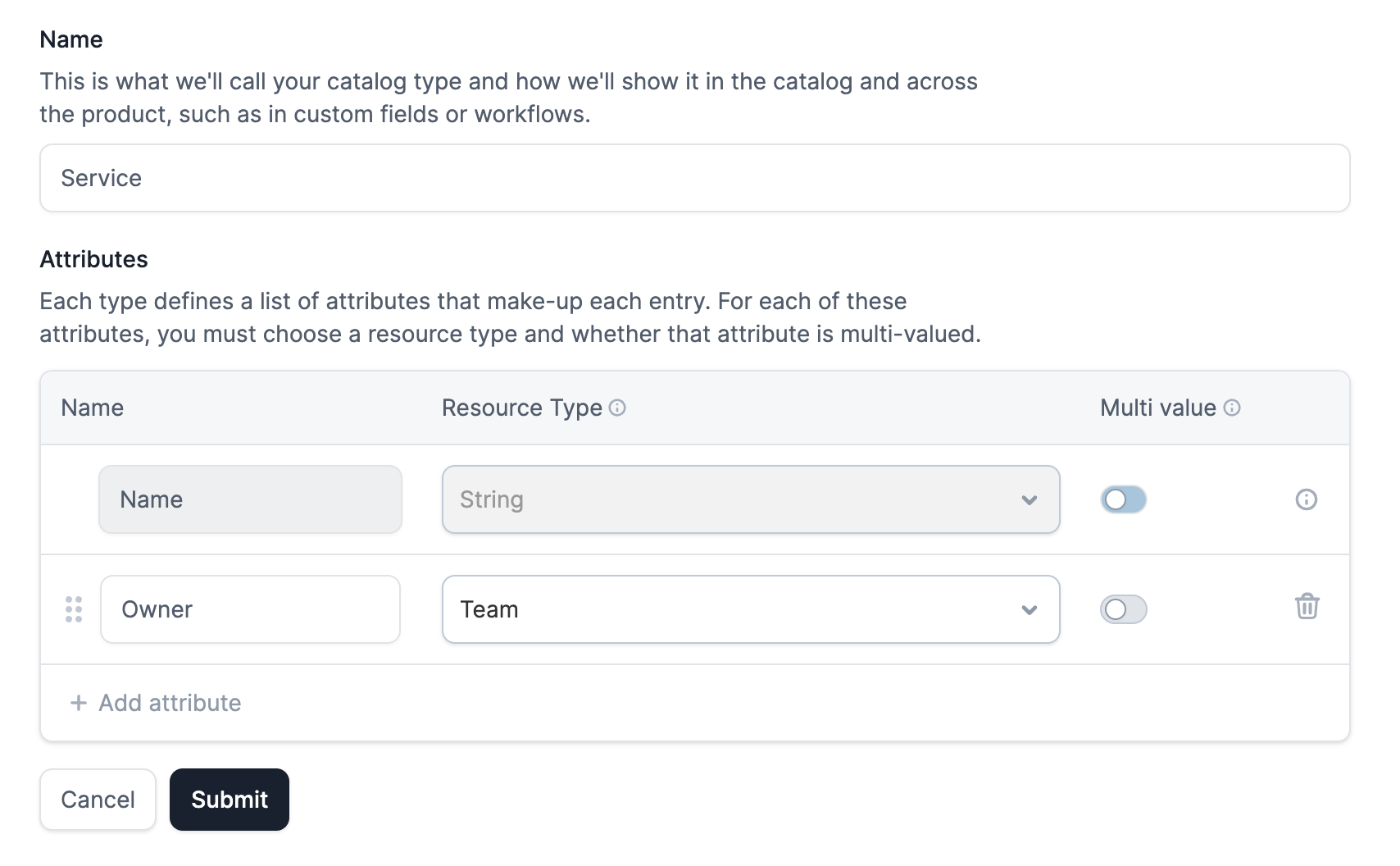
With that in mind, we need to be extremely flexible and allow people to bring their schema rather than asking them to adhere to one we provide. And if we do this, we should be able to load data from wherever they currently have it, rather than having to ask people to both change an existing process as well as how they run it (e.g. moving from a spreadsheet to our catalog) at the same time.
Happy days, though obviously what we’re describing is much more like a general database, foreign keys and column types included. Much more ambitious than a naive, opinionated catalog, but worth it if we have conviction in our reasoning.
Gradual adoption, positive feedback loops
The truth is that building a catalog is hard. If you want to list all services and who owns them, you probably need to actually solve ownership (yuck), and any similar problems are going to be a cross-team effort.
People who already have a catalog are tired. They’re sick of fighting people to update this stuff or having discussions about why it’s important. The last thing they want is another big lift-and-shift.
That’s why even though we know the rest of the product – such as Workflows – can do amazing things once you get the catalog loaded, we wanted to find an adoption carrot that required zero-effort from customers and was attractive to almost any customer we spoke to.
This carrot became “load your catalog data, then you can power custom fields from the catalog”.
Almost all our customers have a field like “Affected services” where they’ve been maintaining a list of service options. Anyone with a catalog is duplicating their service list into incident, and paying the cost of keeping things up-to-date. Let’s remove that friction by powering field options directly from their catalog, making everyone’s lives easier.
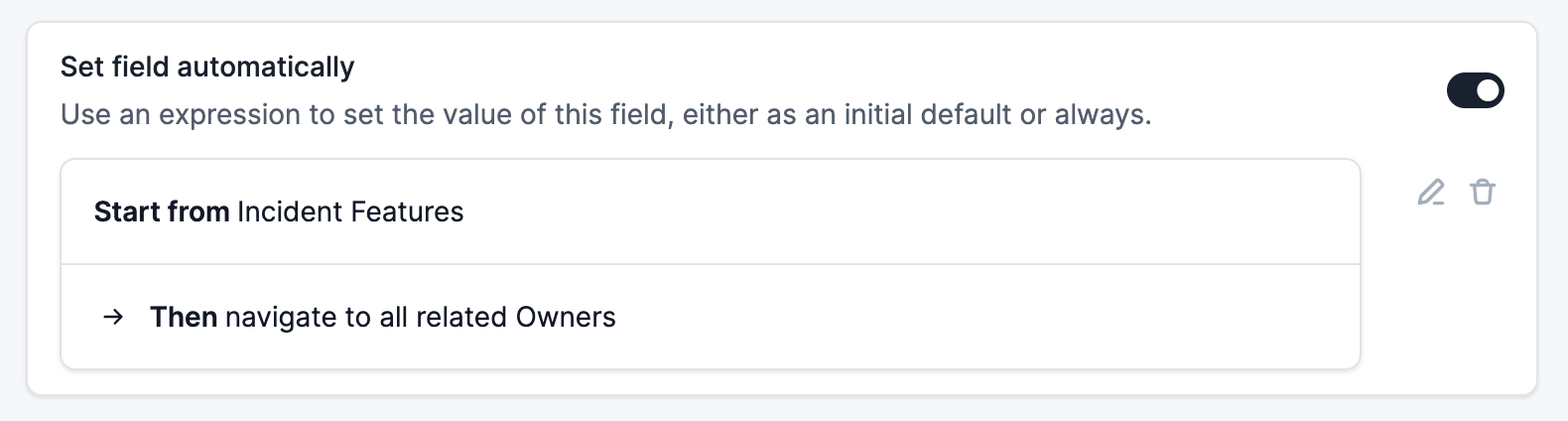
That’s a really feel-good first step, and easily moves to a second: now custom fields are powered by the catalog, you can create other fields such as “Affected team” and say “set this field to be all the teams who own any of the Affected services”. The catalog knows who owns what, so we can stop asking people to manually fill out teams.
Making it possible to gradually adopt the catalog and immediately get value is a fundamental part of our adoption strategy. Then there’s the positive feedback loop when people begin using existing catalog data inside of incident: it’s added incentive for people to invest in the existing catalog, which helps the teams who manage them.
Increasingly powerful as you invest
Finally, we’ve built on the engine described in Building Workflows that is at the core of our product so that catalog data is available everywhere.
That meant implementing a query language that could explore catalog data, with operations such as:
- Navigate: e.g. for each Affected team, find the Owner (builds a list of Teams)
- Filter: e.g. build a list of any Teams which are in X business unit
- Count: e.g. calculate total Affected teams
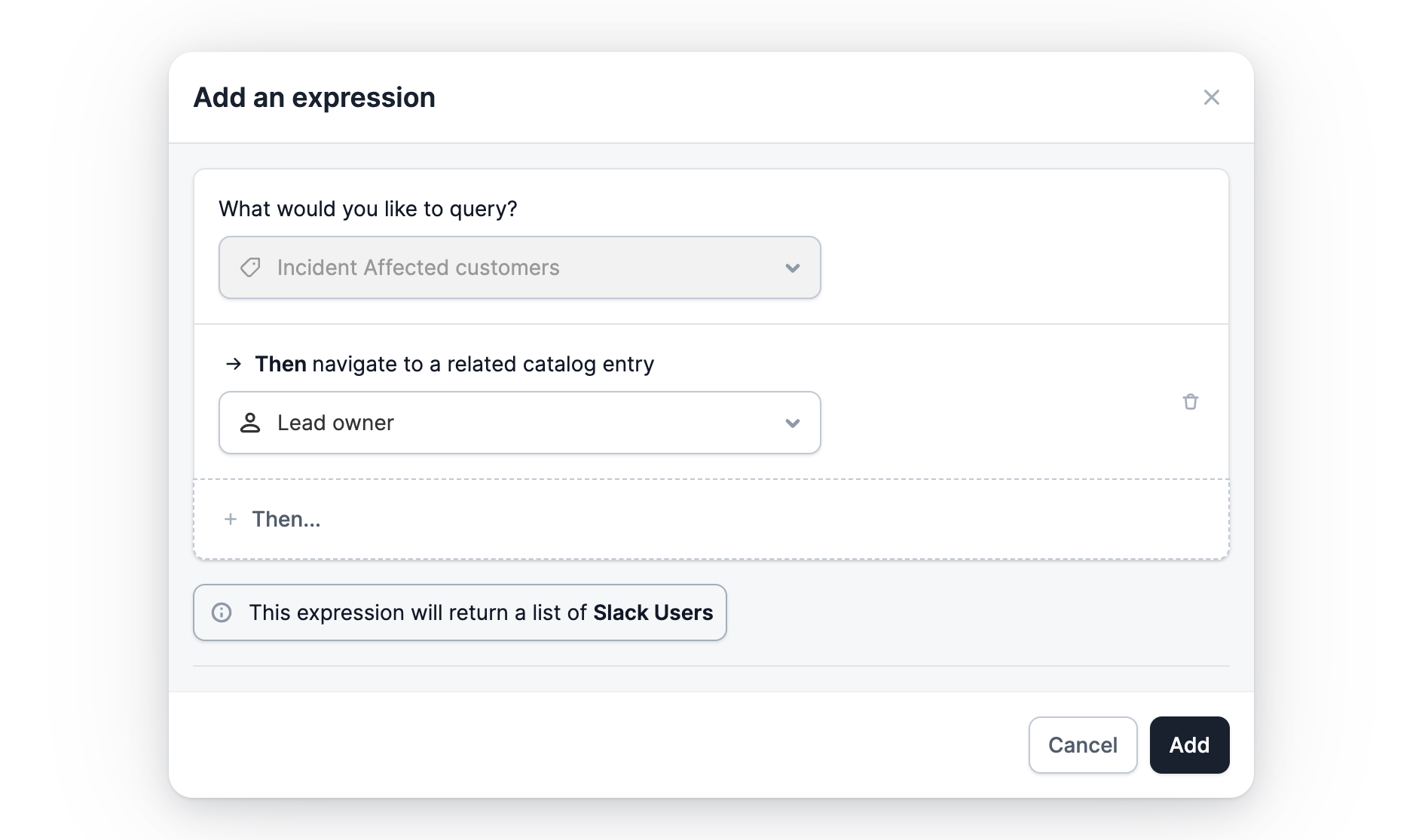
Anywhere in the app you could use expressions – Workflows, or incident Triggers where you can create incidents from external alerts, and more – are immediately catalog ‘aware’, which allows you to use your organisation map across any of your incident response config.
Chris (our CPO) has been going wild building out increasingly cool flows for our account. We now have workflows that notify Customer Success Managers if anyone mentions a customer they manage inside of an incident, and a much improved escalation flow for people across the business to raise incidents and know the right team gets paged.
This stuff has almost unlimited potential and it’s going to take a while for people to figure it out. But it’s already blowing people’s minds, which is really awesome.
So not too bad.
I really did begin this project feeling very nervous. As I said to start, I’d personally witnessed thousands of hours invested in building catalogs that delivered very little value, and I had no wish for us to create yet another time-sink tool.
But with a focus on enabling genuinely useful flows within the context of incident response, and an appreciation for delivering value for each incremental investment people made into our catalog, we’ve built a product that I think is really awesome.
That said, it’s been a grind. And taken much longer than most projects.
Working on a project that demands a big up-front effort rather than small shippable pieces.
— Lawrence Jones (@lawrjones) May 24, 2023
Easy to start doubting you’re working on the right thing or if customers will like it…
Great feeling today then when a customer said “this is exactly what we’re looking for”👌
It’s involved:
- Building terraform-provider-incident specifically so people could manage catalog entries from terraform.
- Creation of the catalog-importer as a ‘universal adapter’ to pull catalog data from any source, be it API, code, Backstage or otherwise.
- Creating integrations for OpsLevel, Cortex and Backstage.
And so much more, including some really complex work supporting for loops in workflows and building out the catalog expression builder.
Having initially felt stressful, I’m super proud of the team for delivering what I believe is the most powerful catalog out of any incident tool you can find on the market.
I even hear Leo may have printed us physical catalog books with a copy of our own homegrown catalog in it. So I guess even if the product falls flat, we’ll have a souvenir to remember the work by!
Do make sure to read the announcement post, if you’ve got this far.
If you liked this post and want to see more, follow me on LinkedIn.