
I’m determined to make a tradition of this, which is why I find myself in an empty office on New Years Eve trying to remember what’s gone by these last twelve months.
I ended “Looking back at 2023” saying “brace for impact” which I had thought meant I was prepared for this year, but in retrospect I wasn’t even close. It’s a common story in start-ups to say “thank god that’s over, next year will be easier!” and be repeatedly wrong, but 2024 was particularly hard.
There is a lot to show for it, though.
The work
This year was about three things: releasing and then extending On-call, conferences and external work, then AI.
Releasing On-call (January-March)
I started 2024 hell bent on getting our on-call product released, having been working on it since July the previous year.
In my previous recap I’d described On-call as “our most ambitious product yet” with one part being the reliability demands that come with a paging system. I was once a Principal SRE running large payment systems and I needed to become that person again as we ramped up for release.
This meant:
- Building a plan to ensure On-call would be rock-solid
- Reviewing every piece of code, adding tests, confirming edge cases
- Running production drills to properly test everything
I’ve got a draft blog post I’m yet to publish called “10 days of load testing and drills” which is all about that last point:

To summarise: I spent several weeks in February working with Martha (an engineer from the team) to kick the living crap out of On-call before we released it.
By a fair margin, these weeks were the most fun I had this year. We had to build out core observability tooling (we had just setup Grafana before the break, but had no dashboards, docs or best-practices) and plan a load testing strategy, then run drills with each engineer in the team trying to repeatedly break the system.
Reliability and system design is my wheelhouse and I was bound to find it fun, but the most rewarding part was working with Martha. She joined the project with almost zero o11y experience and left being one of the most competent at the company, having listened to me drone on about the “importance of dashboard design” and what must’ve seemed like a load of other nonsense.
Working with Martha and each of the team to take proper ownership over On-call was extremely rewarding. It’s a testament to this work that since launch, On-call has exceeded 99.99% availability, even having onboarded hundreds of customers, some pretty large.
We have a “Behind-the-scenes building On-call” blog series that I recommend you check-out, but you can see how well the team met this challenge through their writing:
- Martha with “Our observability strategy” which should be required reading for any team rolling out o11y
- Rory Malcolm on “Continually testing with smoke tests” talking about the automated tests we run continuously to ensure we never miss a page
- Leo Sjöberg on building on the horrible “Complexity of phone networks”
Ask anyone: four nines availability is no joke. There are teams in FANG who will tell you this isn’t possible for company like ours to achieve that, especially for a system like this.
Well, this team proves that wrong.
Building on our release (April-June)
We released On-call on March 5th but it’s easy to release a product, even one with a lot of fanfare, and find no users.
Thankfully that did not happen with On-call, and to give a sense of what’s happened in the 9 months since we launched:
- Over 60% of our customers have bought On-call
- On-call alone is about as big as incident.io was 2.5 years into operation
- We have sent 4M on-call notifications (app notifications, phone calls, SMS, etc)
That’s now, but the first few months after launching were essential! We might’ve just launched an On-call product but (quite entertainingly) so had FireHydrant, and Rootly had soft launched their On-call website (I think in response to our impending launch?) so we were in a crowded space.
That meant several months of dialling into the customer feedback firehose and building whatever was needed to unblock deals, smoothing rough edges found during migration, and generally getting comfortable running this system.
Probably the most noticeable of this work was “Smart Escalation Paths” which introduced dynamic branching into escalations, supporting out-of-hours low urgency pages and a series of other improvements.
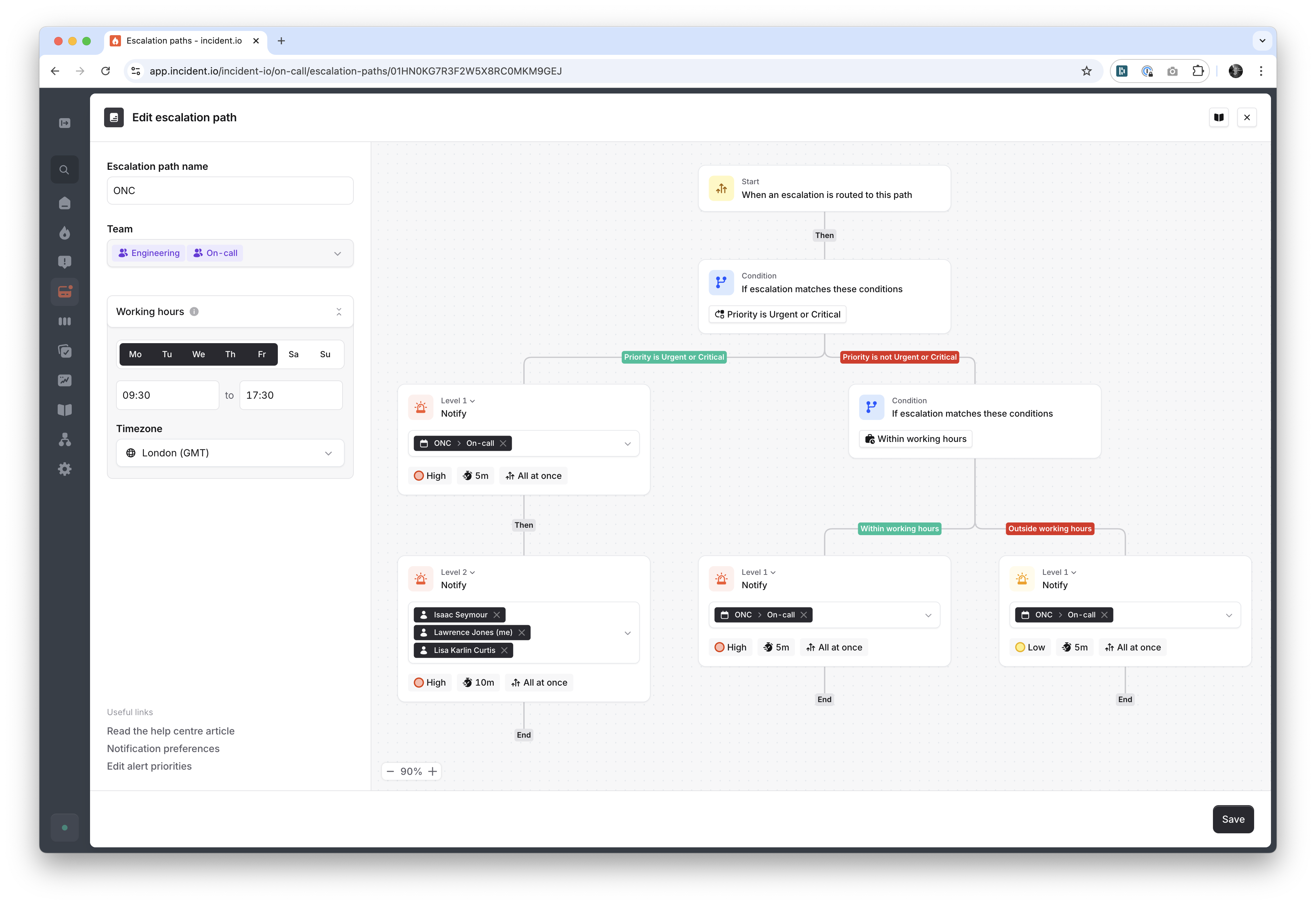
After so long building a product without customers (other than early partners) it was energising to plug back into the ship, feedback, iterate cycle. Honestly just seeing people go “wow, this is so good!” felt rewarding and helped the team feel their achievement.
I also got to dive into mobile app development, something I’d never done before. This involved setting up authentication for the mobile app, a few small features, and eventually giving me the opportunity to build a silly diagram of the custom in-house over-the-air deployment flow we’d built!
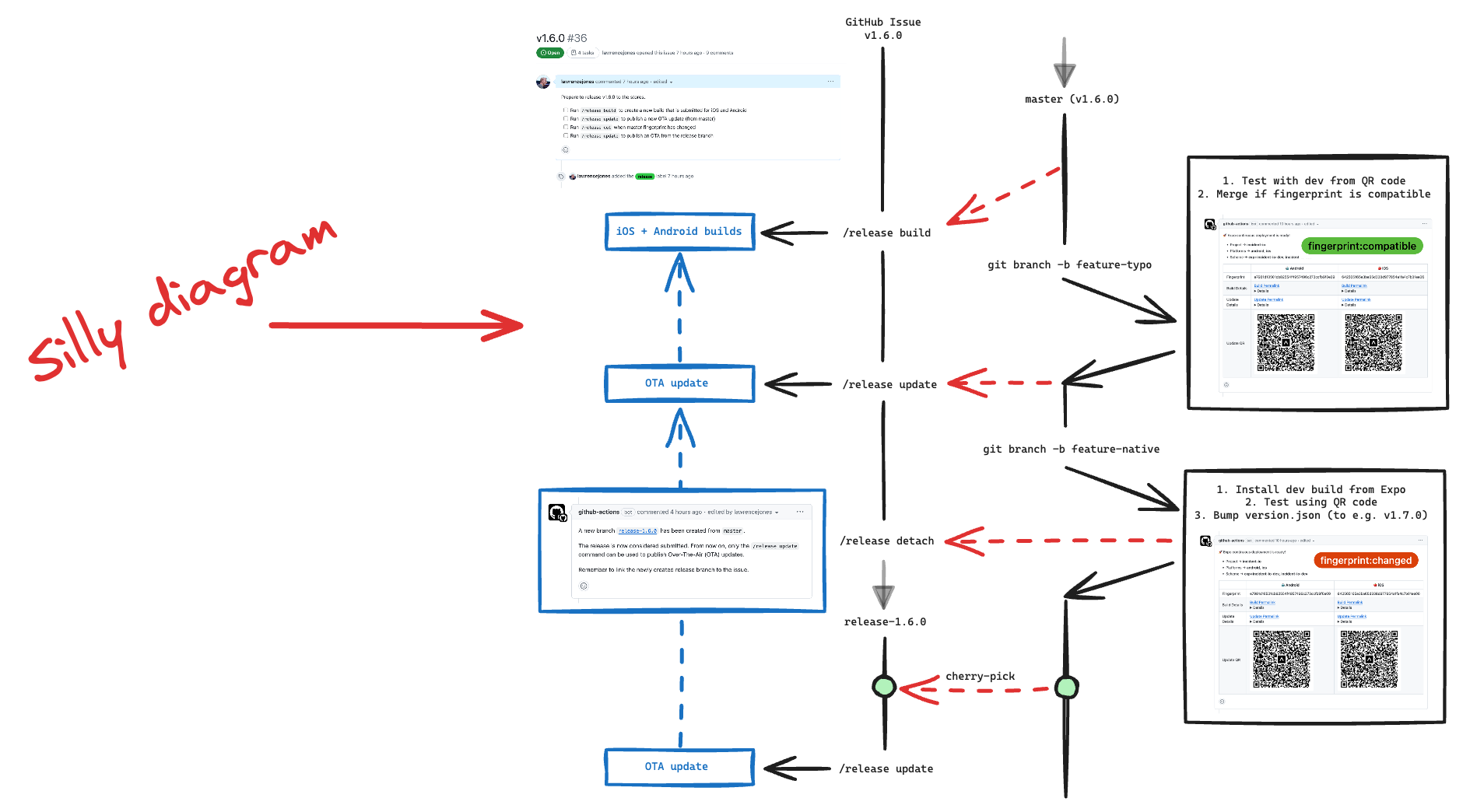
Overall, not a bad quarter!
Scaling to larger customers (July-September)
Thanks to our focus on “human on-call” our On-call product was getting a load of traction with small to medium companies. Crazy huh, imagine making it easy to request cover from your team, or connecting to HR systems and showing holidays alongside your schedules?
But larger companies have more complex setups, and after assigning engineers to On-call sales calls, we found a bunch of small friction-points that made using us at scale difficult.
Luckily the issue wasn’t “can incident.io work for my company” and in fact we are (in my opinion) the most flexible and powerful of the on-call products out there, largely due to our Catalog, meaning you can build whatever routing structure you like. Instead, it was “can I figure out how to make it work” which is a very different type of problem.
On-call in particular is hard for this, as each customer has a unique set of:
- Organisation structure
- Observability/alerting tools
- Alert routing and ownership mechanisms
- Alerting philosophies
You have to solve the problem by fully understanding both across all customers and generically for our platform, and then deep into whatever slice of tools a customer may want to use. Finding solutions that are idiomatic wrt Grafana/Datadog/whatever you may be using requires an expertise in those tools too, in addition with a strong understanding of our system.
We approached the problem by roasting our product, repeatedly setting up accounts and tracking how customers did it, forcing people to develop a ‘healthy impatience’ with our product so they’d balk at the first sign of friction.
Eventually, we rolled out a series of changes that massively helped bigger companies like Intercom access the power of our product more easily.
These ranged from:
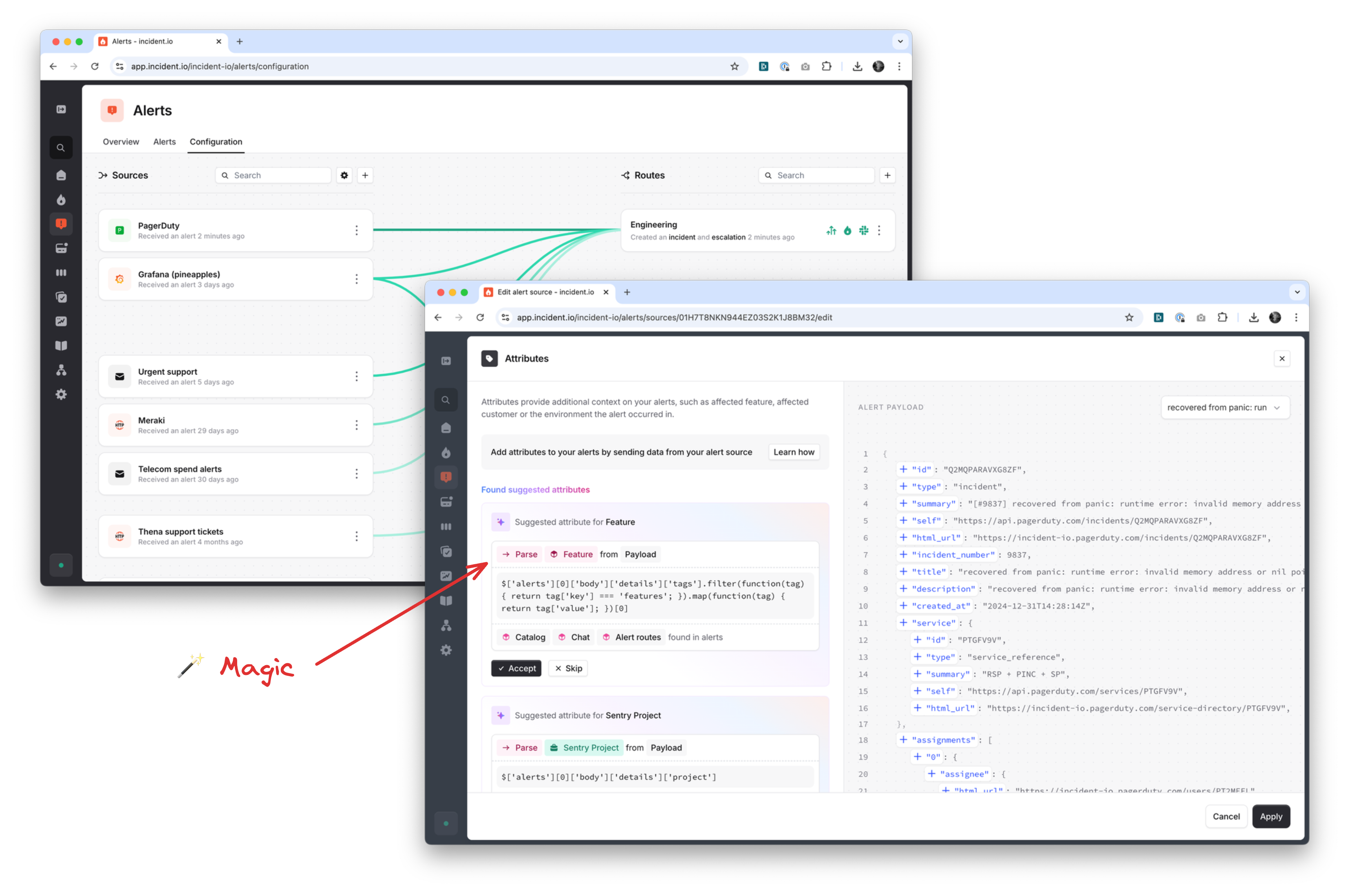
- Redesigning alert config so we visually show how alerts flow from source to routes
- Using AI to automatically parse alert attributes into Catalog fields, so we wire-up Team, Service, Feature or Product automatically
- Adding onboarding sign-posts that help customers find their way to the right configuration
The best part was, after shipping any of these changes, sitting on a call with a customer helping them setup their config and watching as they skipped through the stages, or in some cases had everything automatically wire itself up for them.
I regularly review our larger customer’s configurations and now, after all this, you can visually see how much cleaner their config has become with the product helping them improve it.
Really rewarding, and one of the reasons why we’re closing this year having landed some of our biggest On-call sales yet.
AI (forever)
If you’d asked me in January what my focus would be this year, AI wouldn’t have even made the list. And yet here I am, having spent the last quarter hitting my head against LLMs and building a foundation for what could be our most exciting product yet.
Quite clearly AI changes the scene: auto-generating incident summaries is by far the most widely adopted of the features we built last year, and often the one people quote as the most useful. But there’s so much more that is possible with modern AI tools that can totally change incident response.
That’s why I was asked to help setup a team whose focus would be ambitious, step-changes we could make to the product with AI. Initially I was helping build abstractions, which meant: building eval frameworks that could reliably test prompt behaviour, creating debugging tools that could introspect multi-step AI interactions, and developing architectural patterns like our map-reduce shortlister that efficiently searches data using AI models.
But as we started pulling on the thread of AI we began seeing ever more opportunities to totally overhaul our product. It seemed increasingly obvious that someone was going to reimagine incident response with these tools, and we’d love that person to be… well, us.
So I ended up on the team full time, which meant turning my job into a full time struggle.
That’s because AI engineering is different. Not only are the tools themselves non-deterministic, but figuring out how to use them effectively is a process with very non-linear progress.
Some weeks you’ll make breakthrough after breakthrough, and others you’ll spend days wrestling with prompt engineering only to end up exactly where you started. It’s a humbling experience, especially for engineers used to deterministic systems. Even – and in some cases especially – our most experienced and productive engineers hated it, and we had to build some resilience to that.
We now have a roadmap, though, and unlike On-call we’re talking more publicly about what we’re building. We even have a beautiful homepage at incident.io/ai!
That roadmap breaks into three initiatives:
Scribe (launched)
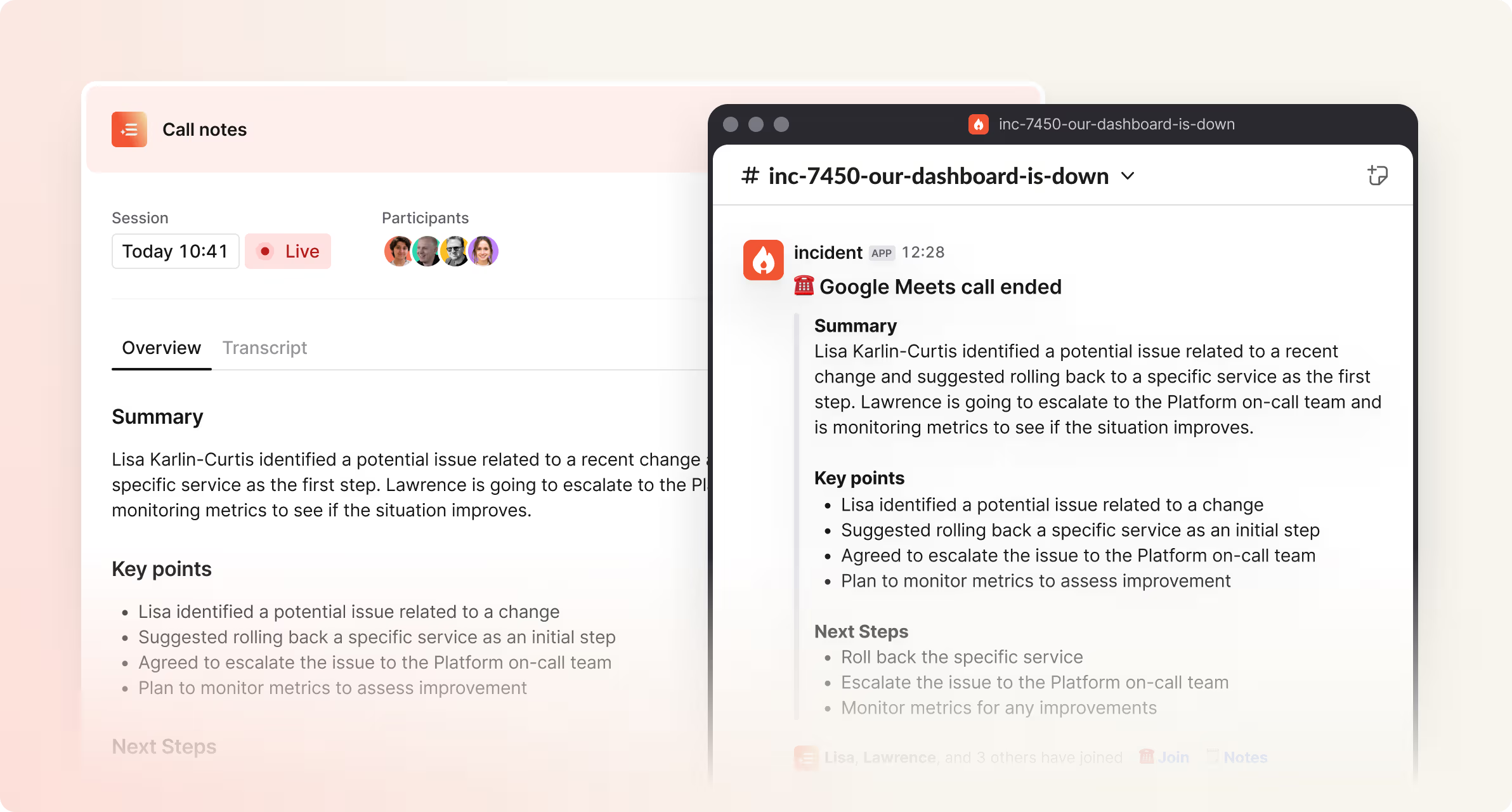
Scribe joins incident calls for you – Zoom, GMeet, whatever – and takes notes, then processes them into key moments and actions that get relayed back to the incident channel.
This is so obviously a perfect use case for AI, with it freeing capacity for humans to do the real work (responding to the incident) while helping them do their job better, by communicating their work more effectively to their colleagues.
While I didn’t work on Scribe myself, it’s built on the AI primitives I’d helped build back in October such as our new prompt framework and eval test suite. It was a good example of how effective those abstractions have been, as it allowed the team to build the AI parts of Scribe very quickly, and even people who hadn’t worked with AI before felt confident in the outcome.
Chat (early access)
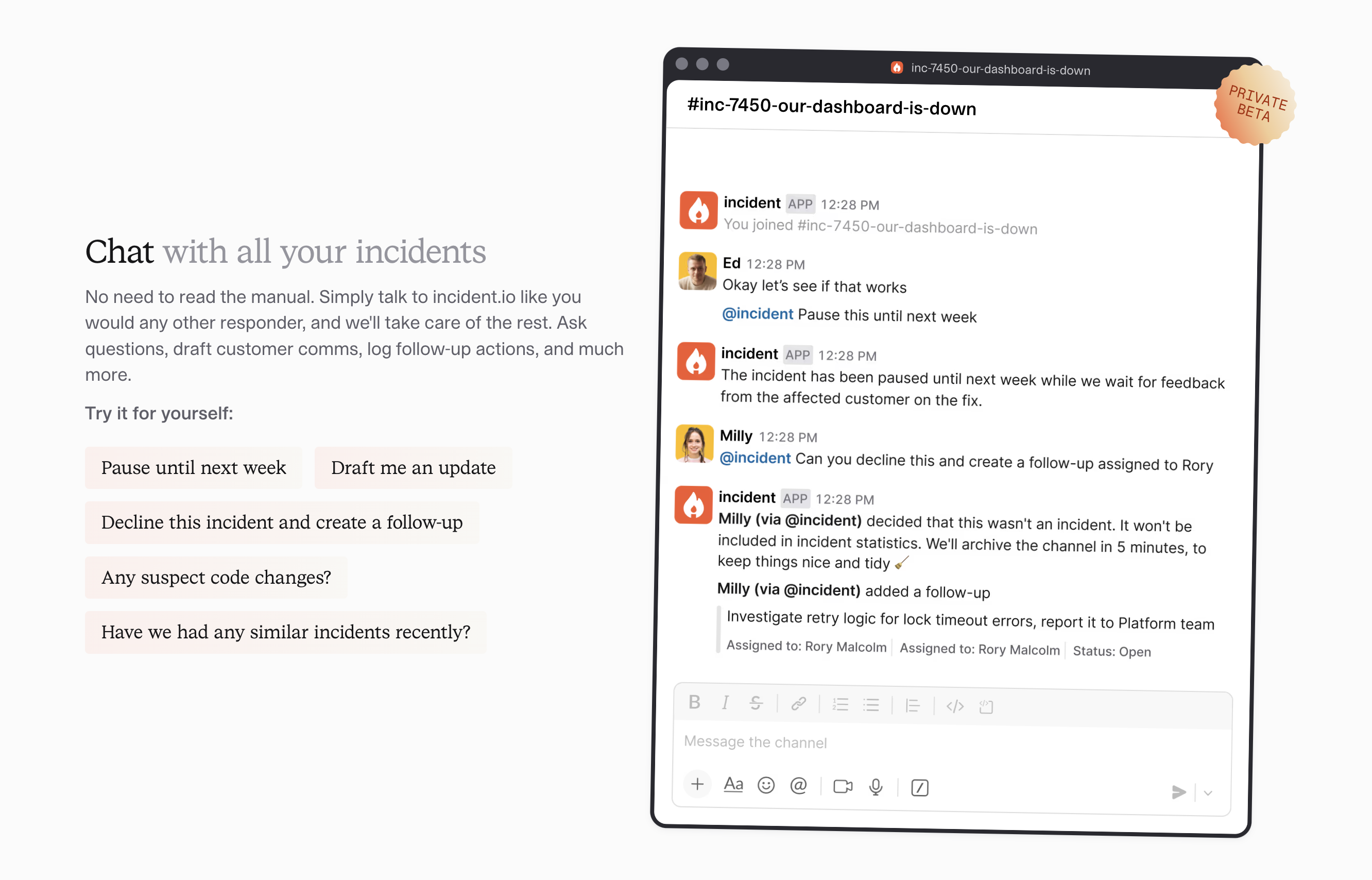
The incident.io team no longer use slash commands to run their incidents. Instead, we chat to our bot and just tell it what we need:
- “@incident.io draft me an update including why Postgres is checkpointing so regularly”
- “@incident.io decline this incident and create a follow-up”
I am biased, but this is the best bot I’m yet to interact with, and people are finding novel use cases for it on the daily.
We have a #copilot-pulse channel that pings every time someone interacts with the bot, along with a grade we assign to each interaction that we monitor for quality.
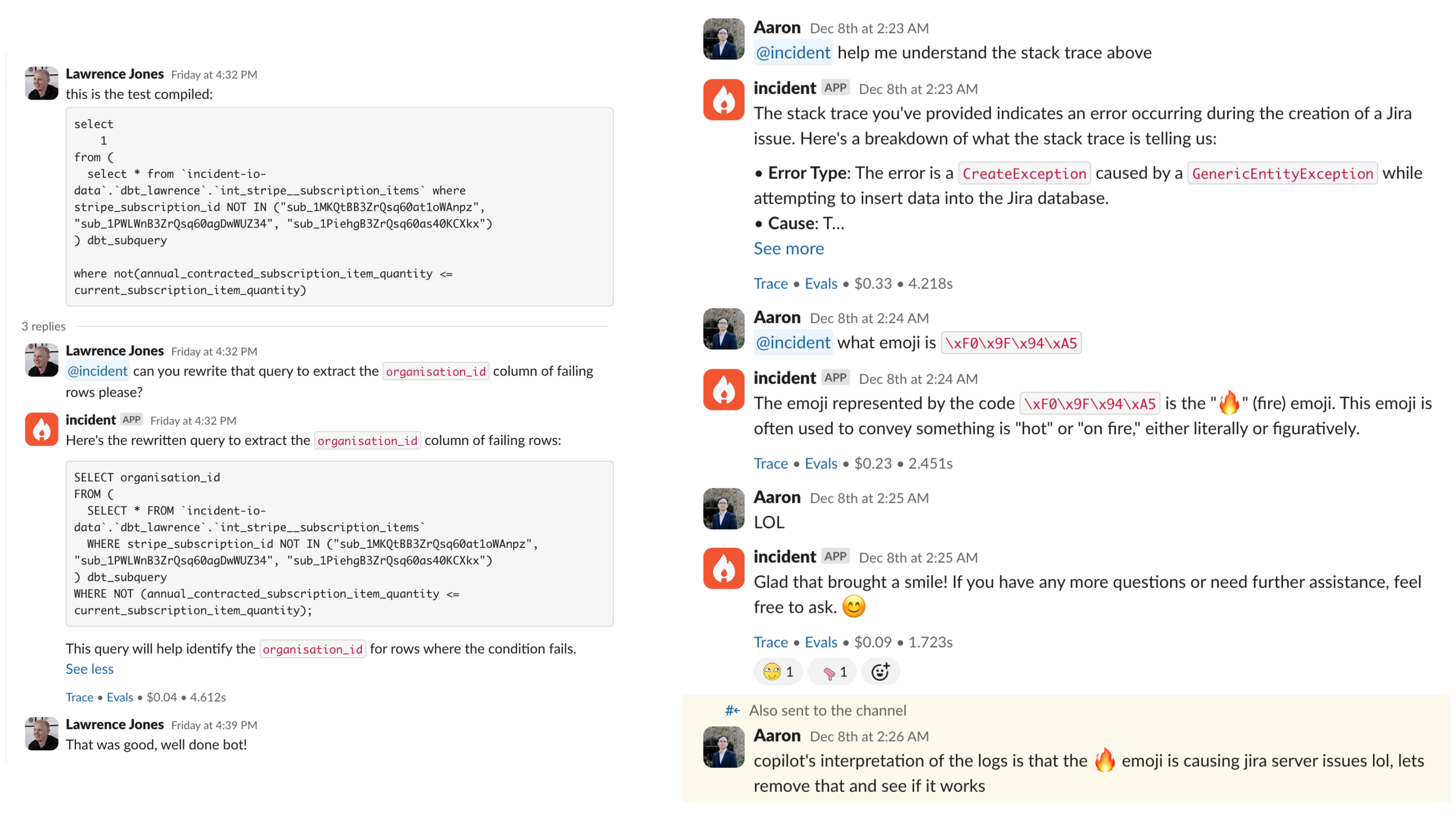
It already does a huge range of things, but some of my favourite interactions are people just asking it for help with the incident. “Fix my query” or “what does that actually mean” where it saves them loads of time to get an answer immediately, one that has all the context of the incident.
Investigation (coming soon)
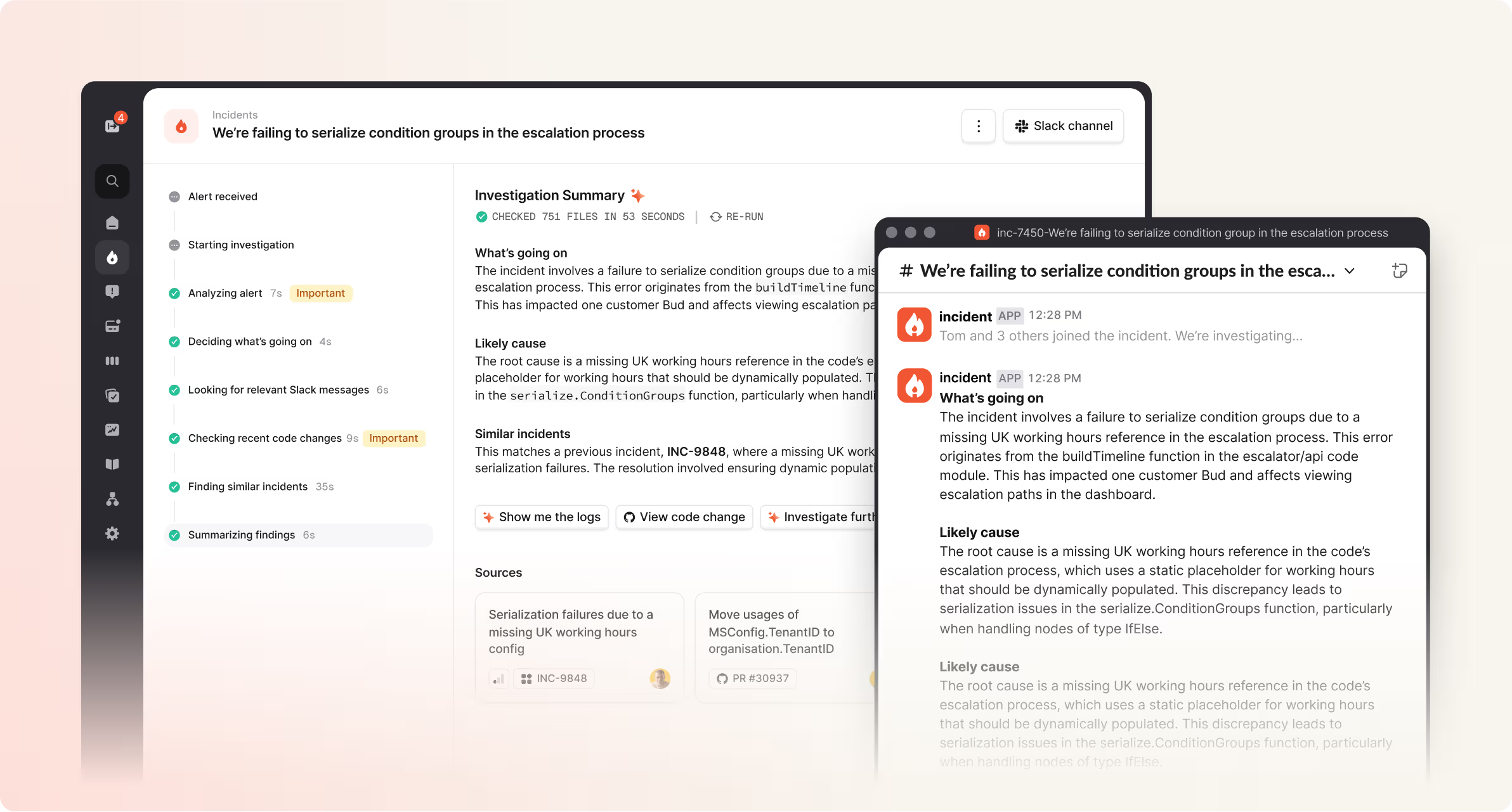
But the really exciting (and challenging) work is in our Investigations system. We’re pushing the boundaries of what’s practical with current AI technology, aiming to have the system automatically check dashboards, read logs, and build a coherent picture of what’s happening before responders even arrive. The goal is ambitious: turn hours-long debugging sessions into minutes by having AI do the heavy lifting.
Personally, this thing has been a challenge. I struggle to sleep when I have an unsolved problem and I’ve gone weeks having no idea how to make this stuff work, where I’ve been dreaming every night of LLM prompts and all sorts. It’s been quite a nightmarish struggle, honestly.
But when it works – when you see the bot correctly identify the root cause of an incident and suggest the exact right action – it feels like we’re glimpsing the future of incident response.
This is definitely turning into “the thing” for 2025. The foundational work we’ve done this year, while often invisible, has set us up to deliver some pretty incredible capabilities to our customers. It’s not just about making existing workflows slightly better – it’s about fundamentally transforming how teams handle incidents.
Everything else
I’m getting dangerously close to needing to leave for NYE, so I’ll keep this short.
Ups and downs
Looking at what we’ve achieved in 2024 is incredible. Even just the success of On-call is massive, ignoring everything else we’ve done.
It’s been really tough, though. We’re in great shape now but things weren’t as rosy at the start of the year, leading to some hard decisions and parting with some of the team in June.
I’d never been close to layoffs before and definitely not in a team as close as ours. This sucked for everyone, a totally shitty experience that leaves some nasty scars for everyone it touches, even when handled well (which, in my opinion, it was).
At this point it’s been 3.5 years since I joined incident, having given myself two days (otherwise known as a weekend) between a 6 year stint at GoCardless that was similarly intense. While I’m focused on the next few months, I want to carve out a proper break for myself next year to reset a bit, as it’s been all consuming for a while now.
Just start-ups, I guess!
Talks and conferences

On a positive note I spoke a lot more this year, and travelled a bunch to do it. Some highlights were:
Architecture at incident.io (Netflix)
I have a huge amount of respect for Netflix engineering which has only been strengthened by my experience working with them as a customer.
It was a big moment for me when I was invited to give a presentation on incident.io’s architecture in our of the internal engineering technical deep-dives.
Over one hundred engineers came to listen to how we built our little incident app, with subjects ranging from Postgres TOAST tables to load testing and modular monoliths. Getting grilled by Principal engineers at one of the infrastructure giants was a massive highlight for me!
Starting from nothing, StaffPlus, New York
LeadDev and StaffPlus are really special conferences to me, having attended them and listened closely in my early career and having always appreciated their work.
New York is a pretty insane flagship location to get invited to talk, but even cooler if you’re talking about how to “start from nothing” with big company initiatives, and pulling the covers back on the experience of a Staff individual contributor in those situations.
I’d also never been to New York, and got to visit a bunch of friends from our office while there.
You can watch the recording here: “Starting from nothing”
Incidents are a whole organization game, Sev0, San Francisco
We ran our own conference this year called “Sev0” which was so much fun.
Firstly, if you’re a company like us with a bunch of top tech logos, SF is where you go to meet your customers. Having dinner with the speakers beforehand was quietly mindblowing for me, when you get an insight into these tech behemoths and how they do things through some of their most senior staff.
I delivered a talk on leveraging organisational context during incidents, a topic particularly close to my heart after fighting tooth and nail to build our Catalog product as a fully flexible schema’d store, all to power use cases like syncing your CRM.
The venue was amazing, the people totally awesome, 10/10 would recommend.
You can see the talk and transcript at “Organization-aware incident response”.
Wrapping up
Looking back, this has been a year of massive change – both planned and unexpected.
We started with the intensity of launching On-call, a product that exceeded even our ambitious reliability goals and has grown to be about as big as incident.io was at 2.5 years. Then came the harder moments in summer that tested our resilience as a team, and eventually dropping myself headfirst into a deep sea of AI.
It’s been really hard, even harder than the previous years and what I’d expected it to be!
Christmas has been a time of reflection for me and I’ve processed a lot, leaving me feeling like I fit a whole load of life experience into the last year.
I’m again reminding myself to be appreciative of the journey, and that the experience I’m having now will be the one I miss in a couple of years, and not to waste any moment of it.
So not making the same mistake again: next year is going to be harder again. I will break myself several times over before fully cracking these AI products, I will repeatedly feel hopeless and like I’m not able to meet the challenge, and there will be curveballs I don’t expect which totally throw me.
If we’ve achieved as much at the end of 2025 as we did this year, though, it’ll have been worth it.
If you liked this post and want to see more, follow me on LinkedIn.