
Compression is a trick that can be used to solve a load of problems. Often, your tools will compress content transparently: most modern browsers ask for gzipped HTTP payload, and some filesystems can be configured to compress blocks without the user ever asking.
Outside of well known use cases, there are a variety of opportunities to improve efficiency or save a load of money by leveraging compression. It’s useful to be aware of common use cases, so you can take these opportunities when they arise.
Migrating logs
As a recent example, my team were migrating logs from one Elasticsearch cluster to another. While not quite Big Data™, this cluster had 10 billion log entries, or some 60TB of raw JSON.
Having experience tackling long-running, large-scale migrations like this, you want to build a process that allows you to ‘save game’ as frequently as possible. This means you can build and run an export process, handling whatever issues will occur (they will, I promise!), then move cleanly on-to the import process. As with exports, your import process will also screw up: so it, too, should be easily re-runnable.
As it is used across a load of GoCardless systems, Google Pub/Sub is a natural fit for this problem. Google’s marketing tagline even sounds like it was written to describe our ideal, decoupled process:
Pub/Sub is an asynchronous messaging service that decouples services that produce events from services that process events.
In Pub/Sub, you publish messages to topics. Each topic can have many subscriptions, which consumers can pull messages from. In the most simple terms, the migration would:
- Export logs from the origin cluster into a (per-index) Pub/Sub topic
- Configure the Pub/Sub subscriptions to retain events (set
retain_acked_messages, see: Replaying and purging messages) so that we may replay them, if our import goes wrong - Import logs by pulling messages from the topic subscriptions
So, what’s this got to do with compression? Like most Cloud services, Pub/Sub charges on usage, which means we’ll incur fees proportional to the data we’ll push through the service.
These charges are:
- $40 per TiB delivered, applied to publish and subscribe
- Google Compute Engine network rates (we’ll ignore these, as they get complicated)
- Seek-related message storage, to retain our messages, at $0.27 per GiB-month
In the best case where we import/export successfully on the first attempt (this won’t, and did not happen), we’ll be charged 2 x $40 x 60TB = $4,800 for message delivery, as it will apply to both publish and subscribe. If we retain our messages for 2 weeks while the migration is on-going, we’ll be charged 0.5 x $0.27 x 60,000GB = $8,100 for message storage.
This leaves a lower-bound of $12,900 to perform the migration.
Now, GoCardless isn’t poor. And as a rule of thumb, you normally want to optimise for engineering hours over infrastructure cost.
But if you can reduce cost with a minimal amount of effort, you should.
Publishing compressed messages
To this end, we made a small change to our migration tool (elastic-toolbox) to
support compression of the messages we published to Pub/Sub.
With error handling removed, this is the publish method, where we apply compression after serialisation:
// Publish takes a message and publishes it to the Pub/Sub topic. If
// compression is enabled, the message payload is compressed, and the
// message is marked with a compress=true attribute.
func (f *pubsubExportTarget) Publish(ctx context.Context, msg Message) error {
data, _ := json.Marshal(msg)
if f.opt.Compress {
data, _ = f.compress(data)
}
// enqueue marks a message as available to be sent, passing it
// to the Pub/Sub client
f.enqueue(ctx, &pubsub.Message{
Data: data,
Attributes: map[string]string{
"compress": fmt.Sprintf("%v", f.opt.Compress),
},
})
return nil
}
The compression itself is dead simple, and almost entirely observability code:
var (
exportPubsubWriteCompressionRatio = promauto.NewHistogram(
prometheus.HistogramOpts{
Name: "elastic_toolbox_export_pubsub_write_compression_ratio",
Help: "Distribution of compression ratio",
Buckets: prometheus.LinearBuckets(0.1, 0.1, 10), // 0.0 -> 1.0
},
)
exportPubsubWriteCompressDurationSeconds = promauto.NewHistogram(
prometheus.HistogramOpts{
Name: "elastic_toolbox_export_pubsub_write_compress_duration_seconds",
Help: "Distribution of time taken to compress hits",
Buckets: prometheus.ExponentialBuckets(0.0625, 2, 8), // 0.0625 -> 16s
},
)
)
// compress applies gzip compression to the incoming data, and instruments
// compression efficiency.
func (f *pubsubExportTarget) compress(data []byte) ([]byte, error) {
defer prometheus.NewTimer(prometheus.ObserverFunc(func(v float64) {
exportPubsubWriteCompressDurationSeconds.Observe(v)
})).ObserveDuration()
var buffer bytes.Buffer
zw := gzip.NewWriter(&buffer)
if _, err := zw.Write(data); err != nil {
return nil, err
}
if err := zw.Close(); err != nil {
return nil, err
}
compressed := buffer.Bytes()
exportPubsubWriteCompressionRatio.Observe(
float64(len(compressed)) / float64(len(data)))
return compressed, nil
}
How much did we save?
As our savings will be proportional to our compression ratio (compressed / original bytes), we care a lot about how compressible our data is.
JSON logs are likely to be very compressible as:
- Logs share many of the JSON keys, which can be de-duplicated (
kubernetes.pod_name) - Values of common log fields might occur very often (
kubernetes.labels.namespace)
Using the modified elastic-toolbox to run an concurrent export of three
different indices, we can use the
elastic_toolbox_export_pubsub_write_compression_ratio Prometheus metric (see
the compress method above) to build a heatmap of compression ratios:
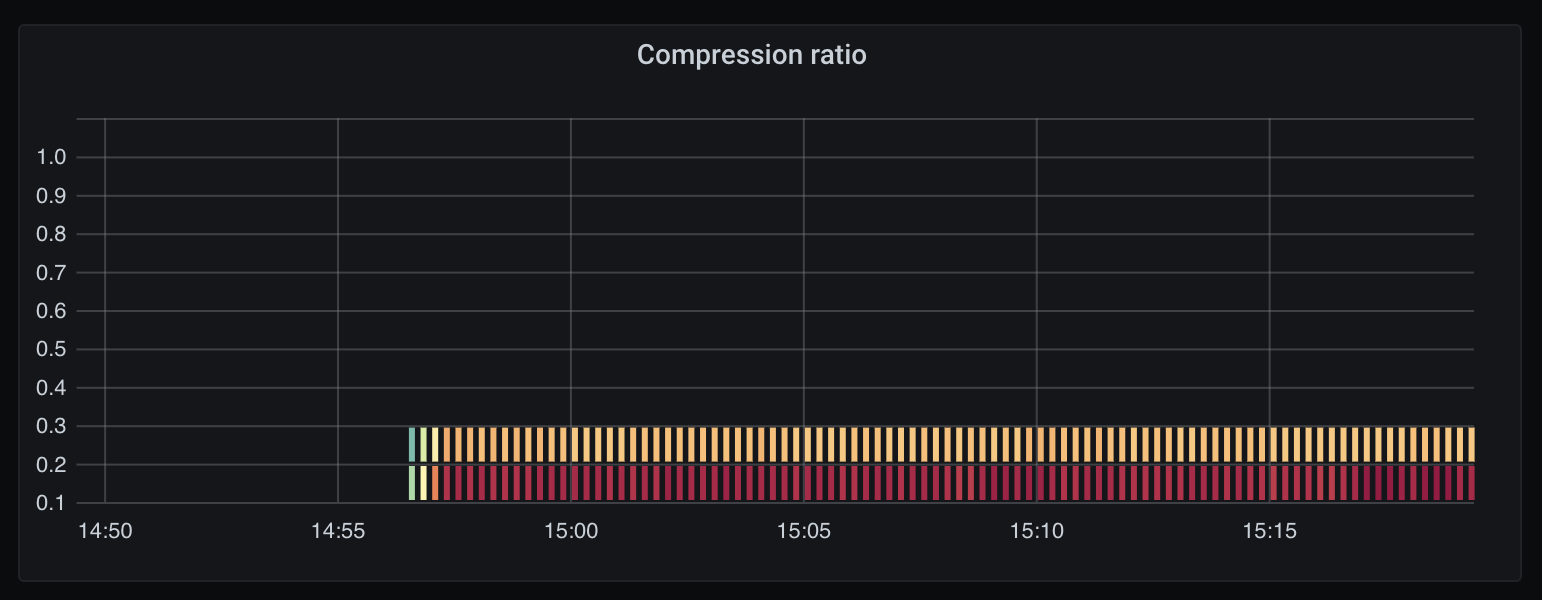
This heatmap shows that all messages compressed to at most 30% the original size. When measured over our entire corpus of logs, we average at a ~12% compression ratio, meaning 1GiB of logs becomes just 120MiB.
Our original bill of $12,900 has become 12% x $12,900 = $1,548.
This means we’ve saved about $11,500.
Explore the data for yourself at this Raintank Snapshot: elastic-toolbox compression.
Next step? Apply fulltime.
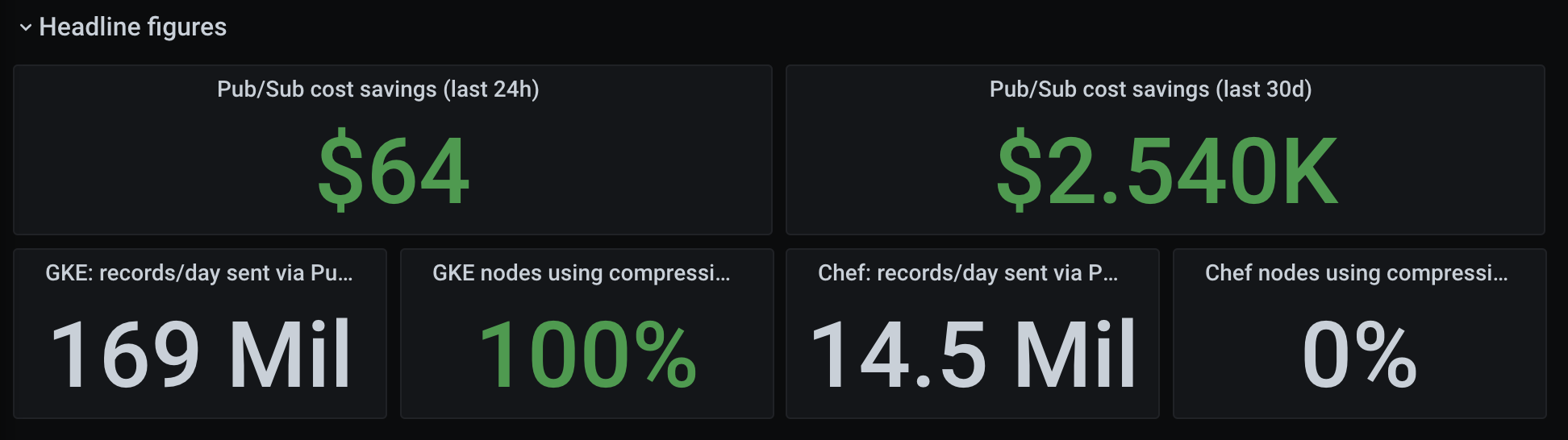
The most obvious next step was to apply this to our logging pipeline all the time. Given we ship container logs straight into Pub/Sub, pulling them out of a subscription into Elasticsearch, we can easily write a fluentd filter that applies the same compression strategy.
My colleague Ben put together an awesome dashboard to track how much we save, which works out to be several thousand a month:
Where else can compression help?
If you work in a Cloud environment, there are so many opportunities to save money by compressing your data.
Beyond logs, another GoCardless example is a tool called draupnir. This service hosts copies of our production databases for load testing and forensic analysis (query plan prediction, etc). Google SSD storage costs $187 per TiB/month, which means every copy of our 5TB Postgres costs $1,000/month.
Draupnir might host several copies at a time, depending on the use cases. We can save a load of money by enabling btrfs compression to transparently compress the filesystem blocks, allowing us to use ~70% less SSD capacity than we may otherwise.
And if you thought compression was limited to cost savings, you’d be wrong! Having suffered from occasional micro-outages when people ran large backfills or built new database indexes, we solved the problem by enabling Postgres WAL compression (see Postgres Underused Features: WAL Compression, or the Postgres Write Ahead Log docs).
The outages were caused by database operations creating a large amount of WAL churn, where the replica would stall while writing the WAL to disk. By compressing the WAL stream, we significantly reduced the IO spikes, allowing the replica to handle the stream without issue.
There are more examples, but I think this paints a good picture.
How does this help you?
Compression is a trade-off, a decision we make to trade CPU for another resource that might be more expensive or less available. The value assigned to CPU, memory, or network bandwidth continually changes, and you’ll need to make this calculation on a case-by-case basis.
This post aimed to cover a scenario where the cost of compression, in both compute resource and time-to-build, was significantly outweighed by the savings it would make. Not all situations will have the same economics, but it takes a few minutes of napkin maths to decide either way.
I hope this case study prompts consideration of compression outside of standard, boring use-cases, and helps to find opportunities where you can apply it to your own systems.
Discuss this post on Hackernews. If you liked this post and want to see more, follow me on LinkedIn.